日記_20260324(甲状腺・黄疸)
甲状腺について
以下の理由から子供の検診に行った。
- 妻が甲状腺の値がもともと悪い
- 甲状腺は遺伝しがち
- 子の退院直前の血液検査の結果で甲状腺の結果が良くなかった
甲状腺の結果は以下で検査される。(AI生成)
TSH(甲状腺刺激ホルモン)
- 下垂体から分泌されるホルモンで、甲状腺に「もっとホルモンを作れ」と指示する。
- 甲状腺機能を評価する上で最も重要かつ鋭敏な指標です。
- FT3・FT4 が低い → TSH が上昇(甲状腺を頑張らせようとする)
- FT3・FT4 が高い → TSH が低下(フィードバックで抑制される)
FT4(遊離サイロキシン)
- 甲状腺が直接分泌するホルモンの主成分。
- Free-T4とも。「遊離(Free)」とは血中でタンパク質に結合していない活性型のことを指す。
- 甲状腺の分泌能力を直接反映する
- 体内では FT4 → FT3 に変換されて使われる
FT3(遊離トリヨードサイロニン)
- FT4 から変換された、実際に細胞に作用する活性型ホルモン。
- 作用はFT4の約4倍強力。
- 代謝・体温・心拍数・神経系の活動に直接影響する
結果甲状腺は特に問題なかった。
- 新生児は、生まれた瞬間にTSHの値が急増(に伴ってFT3,FT4の値も急増)して、その後1日程度でおさまる・・という現象がある。(TSHサージ)
- 出生直後の急激な体温低下に対して熱産生を促進、肺の成熟・代謝の切り替えを促進する作用がある。
- 生後4日目の測定(新生児マススクリーニング検査の一環?)で測定したところ、TSH, Free-T4の値が基準値より高かった。
- この時点では、「正常だが値が下がり切っていない」のか、「甲状腺異常で本当に値が高い」のか判断がつかないため、3週開けて再度血液検査を実施。
- 結果、3週開けた後の血液検査の結果(=TSH, Free-T4の値)は基準値に収まっており、問題ない、つまり前者だったと判定。
- 新生児は、生まれた瞬間にTSHの値が急増(に伴ってFT3,FT4の値も急増)して、その後1日程度でおさまる・・という現象がある。(TSHサージ)
黄疸について
- ついでに新生児の黄疸についても教えてもらった。
- 赤血球について
- 赤血球は、ヘモグロビンという酸素を掴む構造を持ったタンパク質を中に多数内包した構造を持つ。
- 通常、酸素を掴んだ状態のヘモグロビンは、鮮やかな赤色であり、
- 酸素を放出した状態のヘモグロビンは、茶褐色に見える。
- 赤血球は、ヘモグロビンという酸素を掴む構造を持ったタンパク質を中に多数内包した構造を持つ。
- ヘモグロビンについて
- 赤血球が壊れると、赤血球内のヘモグロビンが放出され、グロビンとヘムに分解される。
- ヘムが分解され、ヘムからFeが回収された残骸が、ビリルビンと呼ばれる、黄疸の色を呈する物質である。
- ビリルビンは、通常であれば、以下の順序で排泄される。
- 赤血球が壊れてヘモグロビンが放出される
- ヘモグロビンが分解され、間接ビリルビンが生成される。これは脂溶性であり水に溶けない。
- 肝臓で間接ビリルビンが直接ビリルビンに変換される。これは水溶性である
- 水溶性になった直接ビリルビンが、腸で分解され、便・尿として排泄される。
- 黄疸が発生するメカニズム (=ビリルビンが蓄積するメカニズム)
- 出生後に大量にビリルビンが生成される
- 胎児は、酸素の薄い胎内で親の酸素を横取りできるように、通常のヘモグロビンよりも酸素との親和性が高い特別なヘモグロビンを持っている。
- 出生後は、この特別はヘモグロビンは不要になるため、出生直後に大量のヘモグロビンが分解され、大量にビリルビンが産生される。
- 肝臓が未熟
- 新生児が肝臓が未熟なため、間接ビリルビン→直接ビリルビンの変換が追い付かず、不溶性の間接ビリルビンが残留してしまう
- 腸の運動が未熟
- 腸の蠕動運動が未熟なため、ビリルビンが再吸収されてしまう
- 出生後に大量にビリルビンが生成される
- 母乳育児が黄疸になりやすい理由
- 母乳の成分に、ビリルビンの分解を抑制する成分が含まれているため。
- 黄疸に対して光線療法が有効な理由
- 肝臓が行っている働きを光線療法で代替する アイデア。
- つまり、通常であれば肝臓が、不溶性である間接ビリルビンを、水溶性である直接ビリルビンに変換して排泄できるようにするところ、
- 代わりに青い光を当てることによって、間接ビリルビンを、水溶性である別の物質に変質させることで、排泄できるようにする、という両方。
- ビリルビンは黄疸色であり、ということは逆に青から青緑の光をよく吸収する。吸収率の良い青い光を当てることで、ビリルビン分子が構造変化を起こすためのエネルギーを効率的に与える。
日記_20260305
妻が無事出産した。よかった。。
3/4(水) 22時前の院内消灯とともに帰宅。
行く当てもなく西荻窪の家系に行く。一人でラーメンに行くのも少なくなるかと思い。
相変わらず玉ねぎもキュウリの漬物もおいてなく悲しい思いをする。
私がのんきにラーメンを食べている間に、妻の初期の陣痛?が始まっていたことを後から知る。この時は5分間隔。
ただ、痛みに耐えかねて麻酔を入れてもらったところで陣痛自体止まってしまったようで、それ以上は進まず。翌日へ。
翌日3/5(木)、妻は4時ごろようやく少し寝れたところ、朝5時にまた起こされて、
通常の計画出産の段取り通り、6時頃から陣痛促進剤開始→7時破膜処置 と処置が進んだとのこと。結果、中断されていたところから陣痛が始まった形で、朝7時頃にはすでに陣痛が2,3分間隔に。
看護師さんからは「初産の人は朝から始めても15時くらいだから、ご主人は9時ぐらいに来るで全然大丈夫、それでもかなり待つ」と言われていたところ、
6時にLINEして二度寝して7時過ぎに起きたらもう陣痛2分間隔まで来ているとのことでめちゃめちゃに焦る。
慌てふためいてタクシーで病院に向かう。二度寝で立ち会えなかったとすると一生の不覚、どうか間に合いますように・・・とタクシーで祈ること20分。結局8時過ぎについたが引き続き2分間隔のままだったようで、九死に一生を得る。
妻はこの時点でだいぶ陣痛がつらそう。2分に1回30秒の痛みが来るのでおちおち寝ることもできず。モニタで計っている外測陣痛の値がきれいに周期的に上下していた。フーリエ変換できそう。
「30秒では陣痛の持続が弱いので、我慢できるなら麻酔は追加せずにこのまま我慢したほうが早く進む」と看護師さんに言われ、麻酔は我慢してしばらく耐える。結果、9時過ぎには期待通り陣痛の持続時間が1分強ぐらいまで伸びてきたが、一方で陣痛そのものも激痛になってしまう。妻がベッドのへりにしがみついて小鹿のように震えていてかわいそうだった。普段あまり余裕のないところは見せない妻だがこの時ばかりは本当に痛そうだったので、よっぽど痛いのだと思われる。無痛分娩とは・・・
痛すぎるので麻酔を複数回追加してもらったが、効いてくるのに30分程度かかり、しばらく地獄。下にした方の半身によく麻酔が回るようで、5分おきに寝返りを打ってみたり、右側の効きが悪いので右側を長めに下にしてみたり・・と健気な努力をしつつも、しばらくは激痛で、「30秒たった、もう半分来たよ!」「痛いけど深呼吸して赤ちゃんに呼吸送るよ~」「痛いけど痛い分だけ進んでる証拠だよ!」「よく頑張った、次来るまでにこの時間でしっかりクールダウンするよ~」等、筋トレみたいな声援を送りつつ耐えてもらう。この間妻はずっと小鹿。
10時過ぎには麻酔が効いてきたようで、ちょっと落ち着いてくる。痛いところが右側からお尻側に変わったとのことで、これは痛かった分進んだのでは?と進展を感じる。が、ここに来て赤ちゃんの心拍が100-110くらいまで下がってきて(普段は120-150くらい)、看護師さんたちが慌て始める。先生も2人来ていただいて、内診で「もう出始めてるからこのまま生んじゃいましょう!」とのことで急遽分娩室へ。やや不穏な雰囲気が漂っていたが妻には言わないでおく。
分娩室はピンク一色。先生・看護婦さん・助産師さん含め10人くらいに囲まれる。助産師さんの一人が「メス!」の手(両手の甲を外に向けるやつ)で体制に入っていて、本当にやるんだ・・と思う。
先生から、「お母さんの体の準備ができるよりはやく赤ちゃんが生まれたがってるみたいで赤ちゃんがちょっと苦しそう。緊急帝王切開も考えたがもう出かかっているのでこのまま自然分娩で行きましょう」と言われる。いきなり"帝王切開"のワードが出てきて夫婦ともに!?!?になる。そんな事態だったのか。。ただ、予備室で下がっていたあかちゃんの心拍も、分娩室で再度モニタすると正常に戻ってきていて一安心。この十数分で急に子宮口がひらいたのかな。よかった。このころに麻酔が十分回って痛みはなく落ち着けた。
助産師さんが的確にいきみ方を指導してくれて、いよいよお産に入る。横目には腹筋・上体起こしの動きに近いように見えた。助産師さんはダイレクトにお腹(赤ちゃんの足があるであろうあたり)を押し込んでいて総力戦な感じ。先生からいきむの上手!とほめてもらう。いきむのに上手いとか下手とかあるのか、、?と半信半疑のまま私も耳元で「いきむの上手だね、才能あるよ」「安産家系だから大丈夫だよ」とささやく。前々から「骨盤がゆるゆるで一度寝ると次起きるときに股関節が外れそうになる」、という話を妻から聞いていたが、あれが出産のときに効いているのかもしれない。骨盤の間を潜り抜けて出てくるので、ここが柔らかいと進みも早いのかなと思ったり。
結果、いきみ数回 * 3セットで生まれる。タイムは4時間15分。先生から「初産でこの時間/この回数で生まれる人いないよ」とほめ(?)られる。分娩のタイミングでは麻酔が十分回って、痛みなくいきむことができたようでよかった。赤ちゃんは白い脂分?まみれで出てきた。あと髪の毛めっちゃ生えてた。ちゃんと産声あげてくれた。声でかいねーとほめ(?)られる。元気なのはよいこと。少しだけ抱っこさせてもらう。ちっちゃいおててだった。ほにゃほにゃすぎで何か間違えると簡単に崩れてしまいそうでどきどきした。
後から卵膜(に包まれた胎盤)とへその緒が出てきた。ゴシップ記事の隅の広告で「脂肪吸引でたまった脂肪がドバドバ!」的なサムネをよく見るが、胎盤in卵膜はあれを血だらけにした感じだった。ゆで卵の殻を表面だけ剥くと白っぽい膜が出てくるが、あれに相当するやつなのだろうか。結構なサイズ感でこれだけで1kgはあるかという感じ。積極的に見たいというわけではなかったが、人生で一度しか見れないので見れてよかった。
へその緒も立派とほめてもらった。ちょっとしか見れなかったが、「管が伸びてて、中に青?っぽく見える血液が透けている」ような感じ。巻貝系の刺身を思い出す見た目だった。予想以上に長かった。
傷を縫ってもらう等事後処置してもらって、20分ほどして予備室へ戻る。やり切った感に包まれ、ようやく休める時間になりしばらく経過観察を兼ねて休憩。途中赤ちゃんが来てくれて、少し抱っこできた。きれいに拭いてもらってよりふにゃふにゃだった。
一時的多呼吸という診断が出たと教えてもらった。多呼吸になるのはあくまで結果で、根本原因は肺の中の羊水が乾ききっていないことによるものだそう。お産が短時間で終わった子や、産道で十分に胸部が圧迫されなかった子、帝王切開で生まれた人などが発生しやすいそうで、我々も短期決戦だったのでそうなってしまった模様。最初に顔を見た時点ではもう元気に呼吸していて安心。最初心拍が少し下がった話も、今元気なら大丈夫で尾を引くような話ではないとのこと。
落ち着いたところで産科病棟の4人部屋へ移動。ちょっと熱があるのと、産後の後陣痛がつらくなってきた模様。母方の両親、父方の両親にそれぞれお見舞いにお越しいただく。赤ちゃんには会えず残念。私も面会時間終わりの20時に合わせて帰宅。
===
なにはともあれ無事に生まれてよかった。振り返ってみて、
無痛と言いつつだいぶ痛かったな、というのが感想。9時台は本当につらそうだった。自然分娩で経験するであろう最大痛みの8割ぐらいは経験したのでは?という感じ。無痛は「陣痛の痛みを抑えるために麻酔を入れることができる、が、麻酔を入れると陣痛が進まないので長期化しがち」というジレンマがあるようで難しい。痛いけど短期決戦で行くか、ほどほどの痛みで長丁場になるか、どちらがマシか。。ただ、痛い時に頼みの綱がある、という心理的な安心感を持てる点は良かった。(が、結局麻酔が効くにも時間がかかり痛いは痛かった。。反省するとするなら、とにかく判断は早いほうがよい、というくらいか。)
また、産前2週前くらいから結構な頻度で妻のおなかが張っていたが、やはり普通ではなかった様子。入院中もちょっと張っているだけで色んな人から「結構張ってますね~」とリアクションがあり、出産目前のタイミングでさえそんなトーンなので、やっぱり前々から不定期に前駆陣痛っぽい痛みが来るのはちょっと普通ではなく不安定だったのかなと思う。特に夕方~夜に差し掛かった前駆陣痛が来ることが多かった。サバンナで真昼間に子供を産み落とすと食べられるから、基本動物の出産は夜、という話を聞いて、きっとこれも野生の本能なんだろうと勝手に納得する。
もしくは、検診後の夜におしるしが来たり、前駆陣痛っぽい痛みが来ることが多かったので、外からの刺激を受けやすかったのかもしれない。ミニメトロ挿入後も陣痛っぽいものが来ていた。計画出産日の2週前の検診の直後におしるしが来て、もう生まれるか・・・?と2人して覚悟を決めていたので、結局予定日まで耐えて拍子抜けしたものの、結果的に心構えを持つ時間が十分に取れた点は良かった。
全体的に生まれる前が不安定で、生まれるとなったら急に進む、という感じだった。案ずるより産むが易し・・というと頑張った妻に失礼だが、生まれるまでは先行きが読めない感じがあったものの、お産自体は早々に終えることができ、安産家系の血筋に感謝。
先生からも「このスピード感だと自然無痛分娩は麻酔が間に合わないかもしれないから次回も計画出産がいいかも」とアドバイスいただき、次回も課金を心に誓う。
日記_20260304
妻が計画出産に向け前日入院した。
入院すると菜食生活になってしまうので、お昼はランチに出る。
Braceria Sというお店に行った。店員さん、ハキハキなのはよいのだがお水出し忘れたり、前菜出し忘れたり・・
でもラザニア・炭火焼の鶏肉はおいしかった。毎日通勤で前を通っているはずなのに、こんな見落としがあったとは・・・
もう西荻窪は離れるが最後も探索と発見できた。
妻にとっては松庵の家は最後だったが、タクシーが来てあわただしく出てしまった。
最後まで引っ越しの荷造りをしていた。直前まで負荷をかけなくてよいのに・・・
・モニタ
→点滴 (硬膜外麻酔への前振り)
→硬膜外麻酔
→ミニメトロ
→夕食
の順に進む。
おなか張ってますね~といろんな人に言われる。これ普通じゃないのか・・
モニタを見ていると定期的に張っていることがわかる。
出不精な子か甘えん坊な子か。
モニタをつけると、胎児の脈拍、親の脈拍、親の血圧、親の外測陣痛 が一挙に表示されていて面白かった。
どうやって作るんだろう。
胎児の脈拍は120-150くらい。動いていると明らかに拍動数が上がるので面白い。
小動物は心拍が早い・・・の例を感じた
点滴の針が太くて痛そうだった。
硬膜外麻酔はあまり痛くはなかったようでよかった。これが今日のメインイベントだったので無事終了してよかった。
麻酔したあと5分おきに寝返りを打つのは、交互に半身を下にして麻酔を両半身に巡らせるためらしい。
寝返りを忘れていたら片方ばかり効いてしまった様子。
暇だったので病院の仕組みを色々claudeに聞いて調べていた。
・点滴は単にメモリを回すとチューブが圧迫されて、その流速の遅さが上流に伝わって滴下速度も落ちるらしい。
途中に空気が入っているが、
下流の流速が早い→途中の空気の圧縮膨張が始まる前に、それをキャンセルする形で上流からの液滴の滴下速度が上がる・・・
という挙動になる。
途中の空気が、
・空気自体の圧縮膨張性が高くないこと
・空気の体積が小さいこと
が効いている模様。
一つの系だから、と言われたらそれまでだが、シンプルでよくできている。
・SPO2の測り方。
・吸光度で計っている。
・HbO2:酸素と結びついたヘモグロビンと、Hb:酸素と結びついていないヘモグロビンでは、
・光の吸収のピークが異なる。前者は赤外光を、後者は赤色光をよく吸収する。
・逆に考えるとわかりやすい。つまり、前者=HbO2:酸素と結びついたヘモグロビン=動脈血は比較的赤色光を反射するので鮮血色に見える。
・指先で吸光度を測定すると、その吸光度は、
・動脈血による吸光(拍動により時間依存する)
+静脈血による吸光(拍動にやや依存するが動脈血に比べると誤差なので時間依存しないと考えてよい)
+骨・組織による吸光(時間依存しない)
なので、吸光度のAC成分が動脈血による吸光度と分離することができる。
・原理的には吸光度で測定していて、
バックグラウンドを落とすためにDCを落とす工夫をしている・・という位置づけ。
・夕食があった!夜絶食かと思っていたからよかった。
・唐揚げ・・と思いきや大豆から揚げだった。ここから菜食生活が始まる・・・
bashプログラミングTIPS
■APIを叩く
APIを叩く状況として、以下2種類が考えられる。
1.APIを叩いてシステムを状態を変化させたい。
APIの標準出力も標準エラー出力もログファイルに書き込みたい。
ex) oci bv backup create >> ${LOGFILE} 2>&1
2.APIを叩いてシステムの状態を取得したい
APIの標準出力を変数に格納する。標準エラー出力がもしあればログファイルに書き込む。
ex) RESULT=$(oci bv backup list 2>> ${LOGFILE} )
■コマンド展開
・`oci bv backup list`
・$(oci bv backup list)
の2種類が存在する。どちらも違いはないが、後者の方が見やすい・ネストしやすい。
■変数展開
・$BUFF
・${BUFF}
どちらでもOK
■文字列
・"" →中の変数を展開する
・'' →中の変数を展開せず純粋な文字列として処理する
例えば、
BUFF="aaa"として
echo "${BUFF}" -> aaaが出力される
echo '${BUFF}' -> ${BUFF}が出力される
■改行を含んで変数に格納、後続に渡したい場合
BUFF=$(oci bv backup list) #``でもよい
echo "${BUFF}" | jq '.data[].id' # ${BUFF}を""で囲うことで改行が保存されてパイプで渡される
■文字列比較
if [ ]; then で条件比較ができる。 =とか!=とか
ex) if [ "ABC" = "ABC" ]; then
■文字列比較(bash拡張)
if ; then でより便利に。
・&& とか||とかで条件を結合できるように。
・=~ 正規表現を使ったパターンマッチが可能に。
■数値比較
if [ ]; then で数値比較ができる。-eq とか-gtとか
ex) if [ 100 -eq 99 ]; then
■数値計算
$*2 で数値計算ができる。ただし少数は不可だったり、制約はある。
echo $*3
ab(apache benchmark)コマンド
ab(apache benchmark) コマンド
使ってみる
httpサーバを起動
[root@my-instance ~]# docker run -d -p 8080:80 httpd 7d8b496fa936415ef3a2f34c021f01d1345d2ce9a531ad26ac2e4408342ccbbf [root@my-instance ~]# curl localhost:8080 <html><body><h1>It works!</h1></body></html>
abコマンドを実行
リクエスト100回、並列度5で実施。
[root@my-instance ~]# ab -n 100 -c 5 http://localhost:8080/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software: Apache/2.4.62
Server Hostname: localhost
Server Port: 8080
Document Path: /
Document Length: 45 bytes
Concurrency Level: 5
Time taken for tests: 0.188 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 28900 bytes
HTML transferred: 4500 bytes
Requests per second: 531.94 [#/sec] (mean)
Time per request: 9.400 [ms] (mean)
Time per request: 1.880 [ms] (mean, across all concurrent requests)
Transfer rate: 150.13 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.3 0 1
Processing: 1 9 12.1 4 51
Waiting: 0 9 11.8 3 51
Total: 1 9 12.1 4 51
Percentage of the requests served within a certain time (ms)
50% 4
66% 6
75% 8
80% 20
90% 24
95% 48
98% 51
99% 51
100% 51 (longest request)
OCIブロックボリュームのアタッチ・リストア
はじめに
OCIのブロックボリュームのアタッチ・リストアを試す。
以下の順に進める。
・ブロックボリュームを作成、インスタンスにアタッチ ・lv・ファイルシステムを作成のうえ、OSからマウント ・ブロックボリュームのバックアップ・リストアを実行 ・元のブロックボリュームを一度OSからデタッチ ・リストアしたブロックボリュームをアタッチ
ブロックボリューム作成・インスタンスにアタッチ
コンソールからブロックボリュームを作成

作成できたら、「インスタンスのアタッチ」のボタンで 既存のインスタンスにブロックボリュームをアタッチする。 今回はiSCSI接続を使用する。

アタッチが完了後、OSでiSCSI接続のコマンド打鍵が必要。 コンソールの「iSCSIコマンドおよび情報」から必要な情報を確認して打鍵する。(画像を取り忘れたので添付はイメージのみ)


# まだ何も接続されていない状態 [root@my-instance ~]# iscsiadm --mode session iscsiadm: No active sessions. # コンソールで表示された3コマンドを打鍵し、作成したBVとiSCSI接続する [root@my-instance ~]# sudo iscsiadm -m node -o new -T iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 -p 169.254.2.2:3260 New iSCSI node [tcp:[hw=,ip=,net_if=,iscsi_if=default] 169.254.2.2,3260,-1 iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87] added [root@my-instance ~]# sudo iscsiadm -m node -o update -T iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 -n node.startup -v automatic [root@my-instance ~]# sudo iscsiadm -m node -T iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 -p 169.254.2.2:3260 -l Logging in to [iface: default, target: iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87, portal: 169.254.2.2,3260] (multiple) Login to [iface: default, target: iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87, portal: 169.254.2.2,3260] successful. # iSCSI接続が認識された [root@my-instance ~]# iscsiadm --mode session tcp: [1] 169.254.2.2:3260,1 iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 (non-flash)
lv・ファイルシステムを作成のうえ、OSからマウント
https://dev.classmethod.jp/articles/eetann-use-lvm-ebs/
上記を参考にlvmの設定を行う。 パーティション→pv→vg→lv→ファイルシステム→マウント の順に作業する
初期状態
iSCSI接続を行った最初の状態では、以下のような状態。
lsblkにはsdbとして表示される
# [root@my-instance ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 50G 0 disk sda 8:0 0 46.6G 0 disk ├─sda2 8:2 0 8G 0 part [SWAP] ├─sda3 8:3 0 38.4G 0 part / └─sda1 8:1 0 200M 0 part /boot/efi
parted で確認すると、unknownの状態。
[root@my-instance ~]# parted -l モデル: ORACLE BlockVolume (scsi) ディスク /dev/sda: 50.0GB セクタサイズ (論理/物理): 512B/4096B パーティションテーブル: gpt ディスクフラグ: 番号 開始 終了 サイズ ファイルシステム 名前 フラグ 1 1049kB 211MB 210MB fat16 EFI System Partition boot 2 211MB 8801MB 8590MB linux-swap(v1) 3 8801MB 50.0GB 41.2GB xfs エラー: /dev/sdb: ディスクラベルが認識できません。 モデル: ORACLE BlockVolume (scsi) ディスク /dev/sdb: 53.7GB セクタサイズ (論理/物理): 512B/4096B パーティションテーブル: unknown ディスクフラグ:
パーティション作成
[root@my-instance ~]# gdisk /dev/sdb GPT fdisk (gdisk) version 0.8.10 Partition table scan: MBR: not present BSD: not present APM: not present GPT: not present Creating new GPT entries. # 何もないのでパーティションを作るよう促される Command (? for help): ? # コマンド確認 b back up GPT data to a file c change a partition's name d delete a partition i show detailed information on a partition l list known partition types n add a new partition o create a new empty GUID partition table (GPT) p print the partition table q quit without saving changes r recovery and transformation options (experts only) s sort partitions t change a partition's type code v verify disk w write table to disk and exit x extra functionality (experts only) ? print this menu Command (? for help): n # n : 新しいパーティションを作成 Partition number (1-128, default 1): First sector (34-104857566, default = 2048) or {+-}size{KMGTP}: Last sector (2048-104857566, default = 104857566) or {+-}size{KMGTP}: Current type is 'Linux filesystem' Hex code or GUID (L to show codes, Enter = 8300): L # OS固有のHex Code入力を求められる。確認の上 8e00 (Linux LVM) を選択 0700 Microsoft basic data 0c01 Microsoft reserved 2700 Windows RE 3000 ONIE boot 3001 ONIE config 4100 PowerPC PReP boot 4200 Windows LDM data 4201 Windows LDM metadata 7501 IBM GPFS 7f00 ChromeOS kernel 7f01 ChromeOS root 7f02 ChromeOS reserved 8200 Linux swap 8300 Linux filesystem 8301 Linux reserved 8302 Linux /home 8400 Intel Rapid Start 8e00 Linux LVM a500 FreeBSD disklabel a501 FreeBSD boot a502 FreeBSD swap a503 FreeBSD UFS a504 FreeBSD ZFS a505 FreeBSD Vinum/RAID a580 Midnight BSD data a581 Midnight BSD boot a582 Midnight BSD swap a583 Midnight BSD UFS a584 Midnight BSD ZFS a585 Midnight BSD Vinum a800 Apple UFS a901 NetBSD swap a902 NetBSD FFS a903 NetBSD LFS a904 NetBSD concatenated a905 NetBSD encrypted a906 NetBSD RAID ab00 Apple boot af00 Apple HFS/HFS+ af01 Apple RAID af02 Apple RAID offline af03 Apple label af04 AppleTV recovery af05 Apple Core Storage be00 Solaris boot bf00 Solaris root bf01 Solaris /usr & Mac Z bf02 Solaris swap bf03 Solaris backup bf04 Solaris /var bf05 Solaris /home bf06 Solaris alternate se bf07 Solaris Reserved 1 bf08 Solaris Reserved 2 bf09 Solaris Reserved 3 bf0a Solaris Reserved 4 bf0b Solaris Reserved 5 c001 HP-UX data c002 HP-UX service ea00 Freedesktop $BOOT eb00 Haiku BFS ed00 Sony system partitio ed01 Lenovo system partit Press the <Enter> key to see more codes: Hex code or GUID (L to show codes, Enter = 8300): 8e00 # OS固有のHex Code入力を求められる。確認の上 8e00 (Linux LVM) を選択 Changed type of partition to 'Linux LVM' Command (? for help): p # p : 情報表示。パーティションが作成された。 Disk /dev/sdb: 104857600 sectors, 50.0 GiB Logical sector size: 512 bytes Disk identifier (GUID): 6C169F02-9F66-4E80-A226-768DCE2974D9 Partition table holds up to 128 entries First usable sector is 34, last usable sector is 104857566 Partitions will be aligned on 2048-sector boundaries Total free space is 2014 sectors (1007.0 KiB) Number Start (sector) End (sector) Size Code Name 1 2048 104857566 50.0 GiB 8E00 Linux LVM Command (? for help): w # w: write table to disk and exit この処理をもってパーティション作成完了となる? Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING PARTITIONS!! Do you want to proceed? (Y/N): Y OK; writing new GUID partition table (GPT) to /dev/sdb. The operation has completed successfully.
パーティションを作成したことで、lsblkの表示にもsdb1の名前で表れるようになる。
[root@my-instance ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdb 8:16 0 50G 0 disk └─sdb1 8:17 0 50G 0 part #★先ほど作成したパーティション sda 8:0 0 46.6G 0 disk ├─sda2 8:2 0 8G 0 part [SWAP] ├─sda3 8:3 0 38.4G 0 part / └─sda1 8:1 0 200M 0 part /boot/efi
partedの表示にも、指定した通りlinux LVMとして認識される。
[root@my-instance ~]# parted /dev/sdb print モデル: ORACLE BlockVolume (scsi) ディスク /dev/sdb: 53.7GB セクタサイズ (論理/物理): 512B/4096B パーティションテーブル: gpt ディスクフラグ: 番号 開始 終了 サイズ ファイルシステム 名前 フラグ 1 1049kB 53.7GB 53.7GB Linux LVM lvm
pv・vg・lvの作成
pv作成
[root@my-instance ~]# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created. [root@my-instance ~]# pvs PV VG Fmt Attr PSize PFree /dev/sdb1 lvm2 --- <50.00g <50.00g [root@my-instance ~]# pvdisplay "/dev/sdb1" is a new physical volume of "<50.00 GiB" --- NEW Physical volume --- PV Name /dev/sdb1 VG Name PV Size <50.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID NYFPWF-ue2C-QAra-nL2Y-E5g5-a2xr-R8572M
vg作成
[root@my-instance ~]# vgcreate myvg1 /dev/sdb1 Volume group "myvg1" successfully created [root@my-instance ~]# vgs VG #PV #LV #SN Attr VSize VFree myvg1 1 0 0 wz--n- <50.00g <50.00g
lv作成
[root@my-instance ~]# lvcreate --size 5G --name mylv1 myvg1 WARNING: ext4 signature detected on /dev/myvg1/mylv1 at offset 1080. Wipe it? [y/n]: y Wiping ext4 signature on /dev/myvg1/mylv1. Logical volume "mylv1" created. [root@my-instance ~]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert mylv1 myvg1 -wi-a----- 5.00g [root@my-instance ~]# lvdisplay --- Logical volume --- LV Path /dev/myvg1/mylv1 LV Name mylv1 VG Name myvg1 LV UUID XqEIvG-owlZ-lhoJ-M30g-7Uwd-hI6w-TQwhFC LV Write Access read/write LV Creation host, time my-instance, 2024-12-30 13:17:51 +0900 LV Status available # open 0 LV Size 5.00 GiB Current LE 1280 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 252:0
ファイルシステム作成
[root@my-instance ~]# mkfs -t ext4 /dev/myvg1/mylv1 mke2fs 1.45.4 (23-Sep-2019) Discarding device blocks: done Creating filesystem with 1310720 4k blocks and 327680 inodes Filesystem UUID: b6b2a0f7-1562-4211-8eea-618c559d96b4 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done
マウント
[root@my-instance ~]# df -h #事前状態ではdfの結果に何も乗ってこない ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 294M 0 294M 0% /dev tmpfs 335M 12K 335M 1% /dev/shm tmpfs 335M 35M 301M 11% /run tmpfs 335M 0 335M 0% /sys/fs/cgroup /dev/sda3 39G 19G 20G 49% / /dev/sda1 200M 7.4M 193M 4% /boot/efi tmpfs 67M 0 67M 0% /run/user/1000 tmpfs 67M 0 67M 0% /run/user/993 overlay 39G 19G 20G 49% /var/lib/docker/overlay2/e58ec42d0354623fcf4abbb1cfec8a402619b988e5c6316037521c325ebc4611/merged overlay 39G 19G 20G 49% /var/lib/docker/overlay2/0aab146f51b1f57f957bd4d000ead990c297ebc7753f6b3f986df1a43de7c6c8/merged [root@my-instance ~]# mkdir /mountdir-for-mylv1 # マウントポイント用ディレクトリ作成 [root@my-instance ~]# vi /etc/fstab # マウント設定を追加 [root@my-instance ~]# cat /etc/fstab (略) /dev/myvg1/mylv1 /mountdir-for-mylv1 ext4 defaults 0 0 #★viで追加した行 [root@my-instance ~]# mount -a [root@my-instance ~]# df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 294M 0 294M 0% /dev tmpfs 335M 12K 335M 1% /dev/shm tmpfs 335M 35M 301M 11% /run tmpfs 335M 0 335M 0% /sys/fs/cgroup /dev/sda3 39G 19G 20G 49% / /dev/sda1 200M 7.4M 193M 4% /boot/efi tmpfs 67M 0 67M 0% /run/user/1000 tmpfs 67M 0 67M 0% /run/user/993 overlay 39G 19G 20G 49% /var/lib/docker/overlay2/e58ec42d0354623fcf4abbb1cfec8a402619b988e5c6316037521c325ebc4611/merged overlay 39G 19G 20G 49% /var/lib/docker/overlay2/0aab146f51b1f57f957bd4d000ead990c297ebc7753f6b3f986df1a43de7c6c8/merged /dev/mapper/myvg1-mylv1 4.9G 24K 4.6G 1% /mountdir-for-mylv1 #★マウントできた [root@my-instance mountdir-for-mylv1]# dd if=/dev/urandom of=/mountdir-for-mylv1/testfile bs=1M count=100 #★書き込み確認もOK 100+0 レコード入力 100+0 レコード出力 104857600 バイト (105 MB) コピーされました、 2.98914 秒、 35.1 MB/秒 [root@my-instance mountdir-for-mylv1]# ll 合計 102416 drwx------. 2 root root 16384 12月 30 13:19 lost+found -rw-r--r--. 1 root root 104857600 12月 30 13:29 testfile
ブロックボリュームのバックアップ・リストアを実行
この断面で、ブロックボリュームのバックアップを取得・リストアを実行する。
コンソールから「手動バックアップの作成」を選択。

名前だけ決めて作成。

作成されたバックアップからリストアを実行。


ブロックボリュームのバックアップからリストアが作成された。

元のブロックボリュームを一度OSからデタッチ
リストアの確認として、この時点で、先ほど元のブロックボリューム上に作成したテストファイルは削除しておく。
[root@my-instance mountdir-for-mylv1]# rm testfile rm: 通常ファイル `testfile' を削除しますか? y
元のブロックボリュームはいったんデタッチする。

デタッチしようとすると、事前に
・fstabからは抜いておくこと
・(アンマウントしておくこと)
・iscsiのデタッチのコマンドを打つこと
が求められる。(画像を取り忘れたため表記はイメージのみ)
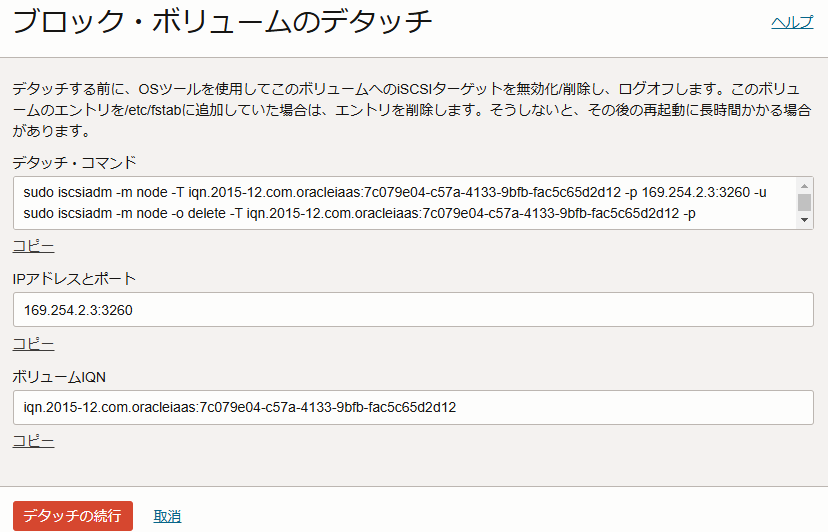
横着して、 ・(アンマウントしておくこと) ・iscsiのデタッチのコマンドを打つこと だけ実施したのち(以下)、「デタッチの続行」を押下。
[root@my-instance /]# umount /mountdir-for-mylv1 #アンマウント [root@my-instance /]# iscsiadm --mode session tcp: [1] 169.254.2.2:3260,1 iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 (non-flash) [root@my-instance /]# sudo iscsiadm -m node -T iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 -p 169.254.2.2:3260 -u # ociから言われたコマンドを実施 Logging out of session [sid: 1, target: iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87, portal: 169.254.2.2,3260] Logout of [sid: 1, target: iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87, portal: 169.254.2.2,3260] successful. [root@my-instance /]# sudo iscsiadm -m node -o delete -T iqn.2015-12.com.oracleiaas:b95d1766-a8c6-490d-8c22-899a3330ce87 -p 169.254.2.2:3260 [root@my-instance /]# iscsiadm --mode session # iSCSI接続がデタッチされた iscsiadm: No active sessions.
この時点でlsblkに表示されなくなる。(デバイスの接続を外したので当然)
[root@my-instance /]# pvs [root@my-instance /]# vgs [root@my-instance /]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 46.6G 0 disk ├─sda2 8:2 0 8G 0 part [SWAP] ├─sda3 8:3 0 38.4G 0 part / └─sda1 8:1 0 200M 0 part /boot/efi
リストアしたブロックボリュームをアタッチ
先ほどと同じ要領で、リストアしたブロックボリュームをインスタンスにアタッチする。 コンソールでアタッチの操作を実行後、コンソール上で指示される以下を打鍵する。
[root@my-instance /]# sudo iscsiadm -m node -o new -T iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12 -p 169.254.2.3:3260 New iSCSI node [tcp:[hw=,ip=,net_if=,iscsi_if=default] 169.254.2.3,3260,-1 iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12] added [root@my-instance /]# sudo iscsiadm -m node -o update -T iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12 -n node.startup -v automatic [root@my-instance /]# sudo iscsiadm -m node -T iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12 -p 169.254.2.3:3260 -l Logging in to [iface: default, target: iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12, portal: 169.254.2.3,3260] (multiple) Login to [iface: default, target: iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12, portal: 169.254.2.3,3260] successful.
この時点でpvs, lvs等の表示が復活する。 UUIDが以前と同じものであることに注意。これが同じだからか特に設定せずとも以前のvgの情報を思い出してくれる?
[root@my-instance /]# iscsiadm --mode session tcp: [2] 169.254.2.3:3260,1 iqn.2015-12.com.oracleiaas:7c079e04-c57a-4133-9bfb-fac5c65d2d12 (non-flash) [root@my-instance /]# pvs PV VG Fmt Attr PSize PFree /dev/sdc1 myvg1 lvm2 a-- <50.00g <45.00g [root@my-instance /]# vgs VG #PV #LV #SN Attr VSize VFree myvg1 1 1 0 wz--n- <50.00g <45.00g [root@my-instance /]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert mylv1 myvg1 -wi-a----- 5.00g [root@my-instance /]# lvdisplay --- Logical volume --- LV Path /dev/myvg1/mylv1 LV Name mylv1 VG Name myvg1 LV UUID XqEIvG-owlZ-lhoJ-M30g-7Uwd-hI6w-TQwhFC #ブロックボリュームをリストアすると、UUIDは以前と同じものを引きつぐ LV Write Access read/write LV Creation host, time my-instance, 2024-12-30 13:17:51 +0900 LV Status available # open 0 LV Size 5.00 GiB Current LE 1280 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 252:0
ただし、マウントには失敗している。前の情報が何かしら残ってしまっている?
[root@my-instance /]# df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 294M 0 294M 0% /dev tmpfs 335M 12K 335M 1% /dev/shm tmpfs 335M 35M 301M 11% /run tmpfs 335M 0 335M 0% /sys/fs/cgroup /dev/sda3 39G 19G 20G 48% / /dev/sda1 200M 7.4M 193M 4% /boot/efi tmpfs 67M 0 67M 0% /run/user/1000 tmpfs 67M 0 67M 0% /run/user/993 overlay 39G 19G 20G 48% /var/lib/docker/overlay2/e58ec42d0354623fcf4abbb1cfec8a402619b988e5c6316037521c325ebc4611/merged overlay 39G 19G 20G 48% /var/lib/docker/overlay2/0aab146f51b1f57f957bd4d000ead990c297ebc7753f6b3f986df1a43de7c6c8/merged [root@my-instance /]# mount -a mount: wrong fs type, bad option, bad superblock on /dev/mapper/myvg1-mylv1, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so.
仕方ないのでコンソールからサーバをリブートしたところ解消。 リブート後は問題なくマウントできていた。
[opc@my-instance ~]$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 294M 0 294M 0% /dev tmpfs 335M 0 335M 0% /dev/shm tmpfs 335M 4.9M 330M 2% /run tmpfs 335M 0 335M 0% /sys/fs/cgroup /dev/sda3 39G 19G 20G 48% / /dev/sda1 200M 7.4M 193M 4% /boot/efi /dev/mapper/myvg1-mylv1 4.9G 101M 4.5G 3% /mountdir-for-mylv1 #マウントできている tmpfs 67M 0 67M 0% /run/user/993 tmpfs 67M 0 67M 0% /run/user/1000
おわりに
UUIDが同じだと・・違うと・・・という話が毎回もやもやするポイント。 次回は横着せずにfstabからも一度外してリブートする。
「docker & kubernetesのきほんのきほん」演習メモ
はじめに
docker & kubernetesのきほんのきほん
を実際にやってみるメモ。 イラストがかわいい。
仕組みと使い方がわかる Docker&Kubernetesのきほんのきほん | マイナビブックス
環境構築
OCI上にインスタンスを作成。既存のVCN(my-vcnに作成)
- 名前:my-instance
- コンパートメント:my-compartment
- イメージ:oracle linux 7.9
- シェイプ:VM.Standard.E2.1.Micro (always free対象)
- VCN:my-vcn
- サブネット:パブリックサブネットmy-vcn
sudo su - yum install docker systemctl start docker systemctl enable docker
dockerコマンドの練習
docker の主なコマンド
# container系 docker container start docker container stop docker container create docker contaienr rm docker contaienr ls (docker ps と同じ) 等・・・ # image系 docker image pull docker image ls 等・・ # volume系 docker volume create docker volume inspect docker volume prune 等・・ # network 系 docker network connect docker network disconnect docker network create 等・・・
コンテナの一連のライフサイクル
docker image pull: イメージをdocker hubからダウンロードdocker container create: コンテナの作成docker container start: コンテナの起動docker container stop: コンテナの停止docker container rm: コンテナの破棄docker run: でpull → create → startまで実行できる。
# httpdのコンテナを立ち上げ。-dでバックグラウンド実行 [root@my-instance ~]# docker run --name apa000ex1 -d httpd Unable to find image 'httpd:latest' locally Trying to pull repository docker.io/library/httpd ... latest: Pulling from docker.io/library/httpd #初回なのでイメージがローカルに存在せず、docker hubからpullする a480a496ba95: Pull complete 3a2663e66670: Pull complete 4f4fb700ef54: Pull complete dbde712f81fb: Pull complete 867b2ea3628d: Pull complete 6bd9d3710aae: Pull complete Digest: sha256:bbea29057f25d9543e6a96a8e3cc7c7c937206d20eab2323f478fdb2469d536d Status: Downloaded newer image for httpd:latest c3f59e50b0b47d2b255fc9cc34c368923d6a2bd3259f2eb025f6a098317b7a50 #コンテナが起動した [root@my-instance ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c3f59e50b0b4 httpd "httpd-foreground" 14 seconds ago Up 10 seconds 80/tcp apa000ex1 [root@my-instance ~]# [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c3f59e50b0b4 httpd "httpd-foreground" 17 seconds ago Up 12 seconds 80/tcp apa000ex1 # コンテナを停止 [root@my-instance ~]# docker stop apa000ex1 apa000ex1 [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c3f59e50b0b4 httpd "httpd-foreground" 58 seconds ago Exited (0) 3 seconds ago apa000ex1 # コンテナを削除 [root@my-instance ~]# docker rm apa000ex1 apa000ex1 [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES # runした際にhttpdのイメージをpullしたので手元にも存在している [root@my-instance ~]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE httpd latest 1bcf11fa154f 3 months ago 148MB
コンテナと通信
# -pでコンテナの80番ポートをホストの8080番ポートに転送 # イメージのpullは上で済なのでコンテナをcreate してstartするだけ [root@my-instance ~]# docker run --name apa000ex2 -d -p 8080:80 httpd 007ff5daf96b211bc568b56c7b849b3d57c403609f184eeb1898da785a3f76d8 [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 007ff5daf96b httpd "httpd-foreground" 4 hours ago Up 4 hours 0.0.0.0:8080->80/tcp apa000ex2 # ローカルホストの8080にcurlすると、コンテナの80番が応答する [root@my-instance ~]# curl http://localhost:8080 <html><body><h1>It works!</h1></body></html> # コンテナの削除 [root@my-instance ~]# docker stop apa000ex2 apa000ex2 [root@my-instance ~]# docker rm apa000ex2 apa000ex2
コンテナにログイン
docker exec -it コンテナ名/bin/bashでコンテナのシェルに入ることができる。コンテナによってはbashが入っていないこともあるので注意
[root@my-instance ~]# docker exec -it apa000ex19 /bin/bash root@8ce616056157:/usr/local/apache2# ls -l / total 8 lrwxrwxrwx. 1 root root 7 Oct 16 00:00 bin -> usr/bin drwxr-xr-x. 2 root root 6 Aug 14 16:10 boot drwxr-xr-x. 5 root root 340 Oct 26 14:59 dev drwxr-xr-x. 1 root root 66 Oct 26 14:59 etc drwxr-xr-x. 2 root root 6 Aug 14 16:10 home lrwxrwxrwx. 1 root root 7 Oct 16 00:00 lib -> usr/lib lrwxrwxrwx. 1 root root 9 Oct 16 00:00 lib64 -> usr/lib64 drwxr-xr-x. 2 root root 6 Oct 16 00:00 media drwxr-xr-x. 2 root root 6 Oct 16 00:00 mnt drwxr-xr-x. 2 root root 6 Oct 16 00:00 opt dr-xr-xr-x. 203 root root 0 Oct 26 14:59 proc drwx------. 2 root root 37 Oct 16 00:00 root drwxr-xr-x. 3 root root 18 Oct 16 00:00 run lrwxrwxrwx. 1 root root 8 Oct 16 00:00 sbin -> usr/sbin drwxr-xr-x. 2 root root 6 Oct 16 00:00 srv dr-xr-xr-x. 13 root root 0 Oct 20 09:31 sys drwxrwxrwt. 2 root root 6 Oct 16 00:00 tmp drwxr-xr-x. 1 root root 19 Oct 16 00:00 usr drwxr-xr-x. 1 root root 41 Oct 16 00:00 var root@8ce616056157:/usr/local/apache2# ls -l /usr/local/apache2/ total 44 drwxr-xr-x. 2 root root 4096 Oct 17 01:21 bin drwxr-xr-x. 2 root root 4096 Oct 17 01:21 build drwxr-xr-x. 2 root root 78 Oct 17 01:21 cgi-bin drwxr-xr-x. 4 root root 84 Oct 17 01:21 conf drwxr-xr-x. 3 root root 4096 Oct 17 01:21 error drwxr-xr-x. 2 root root 24 Oct 17 01:21 htdocs drwxr-xr-x. 3 root root 8192 Oct 17 01:21 icons drwxr-xr-x. 2 root root 4096 Oct 17 01:21 include drwxr-xr-x. 1 root root 23 Oct 26 14:59 logs drwxr-xr-x. 2 root root 8192 Oct 17 01:21 modules root@8ce616056157:/usr/local/apache2# ls -l /usr/local/apache2/htdocs/index.html -rw-r--r--. 1 501 staff 45 Jun 11 2007 /usr/local/apache2/htdocs/index.html root@8ce616056157:/usr/local/apache2# cat /usr/local/apache2/htdocs/index.html <html><body><h1>It works!</h1></body></html>
その他のコンテナも作成してみる
- nginxコンテナ
# nginxのコンテナを作成。-p でコンテナの80番ポートをホストの8004ポートへ転送 [root@my-instance ~]# docker run --name nginx000ex6 -d -p 8004:80 nginx Unable to find image 'nginx:latest' locally Trying to pull repository docker.io/library/nginx ... latest: Pulling from docker.io/library/nginx a480a496ba95: Already exists f3ace1b8ce45: Pull complete 11d6fdd0e8a7: Pull complete f1091da6fd5c: Pull complete 40eea07b53d8: Pull complete 6476794e50f4: Pull complete 70850b3ec6b2: Pull complete Digest: sha256:28402db69fec7c17e179ea87882667f1e054391138f77ffaf0c3eb388efc3ffb Status: Downloaded newer image for nginx:latest c2b03236904a6102d1f308492e64a2b3a2e80c285a4ba1f8740224a02b4f27ad # nginxコンテナが作成された [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c2b03236904a nginx "/docker-entrypoint.…" 42 seconds ago Up 39 seconds 0.0.0.0:8004->80/tcp nginx000ex6 # ホストの8004ポートにcurlするとコンテナの80番ポートが応答する [root@my-instance ~]# curl http://localhost:8004 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> # コンテナの削除 [root@my-instance ~]# docker stop nginx000ex6 nginx000ex6 [root@my-instance ~]# docker rm nginx000ex6 nginx000ex6
- mysqlコンテナ
[root@my-instance ~]# docker run --name mysql000ex7 -dit -e MYSQL_ROOT_PASSWORD=myrootpass mysql 8c9d4ecc76bb5698a6d6124467ca24431dcf6ab5db6892facd75ce7bb47c728d [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8c9d4ecc76bb mysql "docker-entrypoint.s…" 5 seconds ago Up 3 seconds 3306/tcp, 33060/tcp mysql000ex7 # コンテナの削除 [root@my-instance ~]# docker stop mysql000ex7 mysql000ex7 [root@my-instance ~]# docker rm mysql000ex7 mysql000ex7
WordPress + MySQL
- networkを作成
- mysqlコンテナを作成
- wordressコンテナを作成
の順に進む。要約すると以下の3コマンド。mysqlのみ明示的に8.0のバージョンを指定する
docker network create wordpress000net1 docker run --name mysql000ex11 -dit --net=wordpress000net1 -e MYSQL_ROOT_PASSWORD=myrootpass -e MYSQL_DATABASE=wordpress000db -e MYSQL_USER=wordpress000kun -e MYSQL_PASSWORD=wkunpass mysql:8.0 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password docker run --name wordpress000ex12 -dit --net=wordpress000net1 -p 8085:80 -e WORDPRESS_DB_HOST=mysql000ex11 -e WORDPRESS_DB_NAME=wordpress000db -e WORDPRESS_DB_USER=wordpress000kun -e WORDPRESS_DB_PASSWORD=wkunpass wordpress
dockerのネットワークの概念は、「複数のコンテナを同じdocker networkに参加させると、コンテナ同士が通信できるようになる」イメージ?
networkを作成
# networkを作成 [root@my-instance ~]# docker network create wordpress000net1 a4a7b6c3ae8cafe1cd8de42e6e81b72798edda2a95176ee6bca3b75a6d9b4e57 # 作成された [root@my-instance ~]# docker network ls NETWORK ID NAME DRIVER SCOPE d1778e8d9155 bridge bridge local 23b4f3487b4d host host local 196ebccfcf45 none null local a4a7b6c3ae8c wordpress000net1 bridge local # inspectすると、専用のサブネットが切られていることがわかる。 [root@my-instance ~]# docker network inspect wordpress000net1 [ { "Name": "wordpress000net1", "Id": "a4a7b6c3ae8cafe1cd8de42e6e81b72798edda2a95176ee6bca3b75a6d9b4e57", "Created": "2024-10-20T15:51:41.158528026Z", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "172.18.0.0/16", "Gateway": "172.18.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": {}, "Options": {}, "Labels": {} } ]
MySQLコンテナを作成
[root@my-instance ~]# docker run --name mysql000ex11 -dit --net=wordpress000net1 -e MYSQL_ROOT_PASSWORD=myrootpass -e MYSQL_DATABASE=wordpress000db -e MYSQL_USER=wordpress000kun -e MYSQL_PASSWORD=wkunpass mysql :8.0 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password Unable to find image 'mysql:8.0' locally Trying to pull repository docker.io/library/mysql ... 8.0: Pulling from docker.io/library/mysql eba3c26198b7: Already exists 6111251d1d05: Pull complete b669648c0f2f: Pull complete 6f19c425e6ff: Pull complete 530232ef45f9: Pull complete 880d6068231f: Pull complete bb2907e86db3: Pull complete eea32227a5f9: Pull complete e0a236ad6589: Pull complete cb0c5c9ac9cf: Pull complete 05654ed9c105: Pull complete Digest: sha256:bf79508626d6cad5bd82ea762109690e42467b1eefedab27946eccd69ab23069 Status: Downloaded newer image for mysql:8.0 92b35ed65a85495d700cb70a842065644944057547ed139857147895fcc6cc40 [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 92b35ed65a85 mysql:8.0 "docker-entrypoint.s…" 39 seconds ago Up 35 seconds 3306/tcp, 33060/tcp mysql000ex11
wordpressコンテナを作成
[root@my-instance ~]# docker run --name wordpress000ex12 -dit --net=wordpress000net1 -p 8085:80 -e WORDPRESS_DB_HOST=mysql000ex11 -e WORDPRESS_DB_NAME=wordpress000db -e WORDPRESS_DB_USER=wordpress000kun -e WORDPRESS_DB_PASSWORD=wkunpass wordpress c8377fceae5aa4976da710ecc31d57381edddf8f96e9bc0e8852d4474edafef0 [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c8377fceae5a wordpress "docker-entrypoint.s…" 23 seconds ago Up 14 seconds 0.0.0.0:8085->80/tcp wordpress000ex12 92b35ed65a85 mysql:8.0 "docker-entrypoint.s…" About a minute ago Up About a minute 3306/tcp, 33060/tcp mysql000ex11
確認
ホストの8085ポートにブラウザでアクセス
ちなみにこの時点でdocker networkを確認すると、ネットワークにmysqlとwordpressのコンテナが参加していることが確認できた
[root@my-instance ~]# docker network inspect wordpress000net1 [ { "Name": "wordpress000net1", "Id": "a4a7b6c3ae8cafe1cd8de42e6e81b72798edda2a95176ee6bca3b75a6d9b4e57", "Created": "2024-10-20T15:51:41.158528026Z", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "172.18.0.0/16", "Gateway": "172.18.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "92b35ed65a85495d700cb70a842065644944057547ed139857147895fcc6cc40": { "Name": "mysql000ex11", "EndpointID": "37aee9faf349f5c8e6fcc48a11e448a3b9532570cbc1d4cd52e8085d38795f82", "MacAddress": "02:42:ac:12:00:02", "IPv4Address": "172.18.0.2/16", "IPv6Address": "" }, "c8377fceae5aa4976da710ecc31d57381edddf8f96e9bc0e8852d4474edafef0": { "Name": "wordpress000ex12", "EndpointID": "e59133f5eccd3f002faa9b45861afb288cb5924570a4e4d1596aaad2e321285c", "MacAddress": "02:42:ac:12:00:03", "IPv4Address": "172.18.0.3/16", "IPv6Address": "" } }, "Options": {}, "Labels": {} } ]
後片付け
docker stop wordpress000ex12 docker rm wordpress000ex12 docker stop mysql000ex11 docker rm mysql000ex11 docker network rm wordpress000net1
補足
特にバージョンを指定せずにコンテナを起動したところ、mysqlコンテナが落ちていた。
# 特にバージョンを指定せずにコンテナを起動したところ、 docker network create wordpress000net1 docker run --name mysql000ex11 -dit --net=wordpress000net1 -e MYSQL_ROOT_PASSWORD=myrootpass -e MYSQL_DATABASE=wordpress000db -e MYSQL_USER=wordpress000kun -e MYSQL_PASSWORD=wkunpass mysql --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password docker run --name wordpress000ex12 -dit --net=wordpress000net1 -p 8085:80 -e WORDPRESS_DB_HOST=mysql000ex11 -e WORDPRESS_DB_NAME=wordpress000db -e WORDPRESS_DB_USER=wordpress000kun -e WORDPRESS_DB_PASSWORD=wkunpass wordpress # mysqlコンテナが落ちていた [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f7ef514ada96 wordpress "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:8085->80/tcp wordpress000ex12 d7fbeb9e0c80 mysql "docker-entrypoint.s…" 4 minutes ago Exited (1) 4 minutes ago mysql000ex11
mysqlコンテナのログを確認したところ、最新版として使っているmysql9.1はdefault-authentication-plugin=mysql_native_passwordなる変数を持っていないとのこと。バージョン8ではあったはずなのだが、latestでは消えているか指定の仕方が変わっている様子。上記ではバージョンを落として明示的にmysql:8.0を指定して動かしている。
[root@my-instance ~]# docker logs d7fbeb9e0c80 2024-10-20 15:55:12+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2024-10-20 15:55:13+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' 2024-10-20 15:55:13+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 9.1.0-1.el9 started. 2024-10-20 15:55:14+00:00 [Note] [Entrypoint]: Initializing database files 2024-10-20T15:55:14.533840Z 0 [System] [MY-015017] [Server] MySQL Server Initialization - start. 2024-10-20T15:55:14.537197Z 0 [System] [MY-013169] [Server] /usr/sbin/mysqld (mysqld 9.1.0) initializing of server in progress as process 78 2024-10-20T15:55:14.622100Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started. 2024-10-20T15:55:17.205432Z 1 [System] [MY-013577] [InnoDB] InnoDB initialization has ended. 2024-10-20T15:55:21.934438Z 0 [ERROR] [MY-000067] [Server] unknown variable 'default-authentication-plugin=mysql_native_password'. 2024-10-20T15:55:21.936824Z 0 [ERROR] [MY-013236] [Server] The designated data directory /var/lib/mysql/ is unusable. You can remove all files that the server added to it. 2024-10-20T15:55:21.936872Z 0 [ERROR] [MY-010119] [Server] Aborting 2024-10-20T15:55:24.181299Z 0 [System] [MY-015018] [Server] MySQL Server Initialization - end.
Redmine + MySQL
コンテナの起動
#ネットワークの作成 docker network create redmine000net2 #mysql:8.0コンテナの作成 docker run --name mysql000ex13 -dit --net=redmine000net2 -e MYSQL_ROOT_PASSWORD=myrootpass -e MYSQL_DATABASE=redmine000db -e MYSQL_USER=redmine000kun -e MYSQL_PASSWORD=rkunpass mysql:8.0 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password # redmineコンテナの作成 docker run -dit --name redmine000ex14 --network redmine000net2 -p 8086:3000 -e REDMINE_DB_MYSQL=mysql000ex13 -e REDMINE_DB_DATABASE=redmine000db -e REDMINE_DB_USERNAME=redmine000kun -e REDMINE_DB_PASSWORD=rkunpass redmine # ブラウザでインスタンスの8086ポートにアクセス。デフォルトユーザはadmin/admin
後片付け
docker stop redmine000ex14 docker rm redmine000ex14 docker stop mysql000ex13 docker rm mysql000ex13 docker network rm redmine000net2
補足
コンテナのポートにアクセスするには、
- 起動時に
-p 8004:80オプションをつけてローカルホストのポートにフォワーディングするか、 docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mysql000ex13でコンテナに振られたIPを調べて、そのIPとポートに対してアクセスする- ローカルサーバ上でポートフォワードする
等が考えられる。
すでに上がっているコンテナに対しては2点目3点目で対応できる。
# mysql clientのインストール rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 #最近のGPGキーをインストール https://qiita.com/Code_Dejiro/items/c97c400b92a85dce4468 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2023 #最近のGPGキーをインストール yum install -y https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm yum install -y mysql-community-client # コンテナのIPを確認:方法その1 [root@my-instance ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mysql000ex13 172.20.0.2 # コンテナのIPを確認:方法その2 [root@my-instance ~]# docker network inspect redmine000net2 | jq '.[].Containers[] | select(.Name == "mysql000ex13")' { "Name": "mysql000ex13", "EndpointID": "c9fa2b0113e2fedca2fff257ee28d0273b511089f6c5010a436cadb5161c174c", "MacAddress": "02:42:ac:14:00:02", "IPv4Address": "172.20.0.2/16", "IPv6Address": "" } # コンテナのポートを確認 [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9304fc614123 redmine "/docker-entrypoint.…" 17 minutes ago Up 17 minutes 0.0.0.0:8086->3000/tcp redmine000ex14 f0b2890a3fa9 mysql:8.0 "docker-entrypoint.s…" 52 minutes ago Up 52 minutes 3306/tcp, 33060/tcp mysql000ex13 # mysqlクライアントからコンテナのIP:3306に接続。色々テーブルができていて、先ほど試しに作ったredmineプロジェクトのデータも入っている。 [root@my-instance ~]# mysql -h 172.20.0.2 -u redmine000kun -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 18 Server version: 8.0.40 MySQL Community Server - GPL Copyright (c) 2000, 2024, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | performance_schema | | redmine000db | +--------------------+ 3 rows in set (0.08 sec) mysql> use redmine000db; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +---------------------------+ | Tables_in_redmine000db | +---------------------------+ | ar_internal_metadata | | attachments | | auth_sources | | boards | | changes | | changeset_parents | | changesets | | changesets_issues | | comments | | custom_field_enumerations | | custom_fields | | custom_fields_projects | | custom_fields_roles | | custom_fields_trackers | | custom_values | | documents | | email_addresses | | enabled_modules | | enumerations | | groups_users | | import_items | | imports | | issue_categories | | issue_relations | | issue_statuses | | issues | | journal_details | | journals | | member_roles | | members | | messages | | news | | projects | | projects_trackers | | queries | | queries_roles | | repositories | | roles | | roles_managed_roles | | schema_migrations | | settings | | time_entries | | tokens | | trackers | | user_preferences | | users | | versions | | watchers | | wiki_content_versions | | wiki_contents | | wiki_pages | | wiki_redirects | | wikis | | workflows | +---------------------------+ 54 rows in set (0.00 sec) mysql> select * from projects; +----+-------------+-------------+----------+-----------+-----------+---------------------+---------------------+-------------+--------+------+------+-----------------+--------------------+------------------------+------------------------+ | id | name | description | homepage | is_public | parent_id | created_on | updated_on | identifier | status | lft | rgt | inherit_members | default_version_id | default_assigned_to_id | default_issue_query_id | +----+-------------+-------------+----------+-----------+-----------+---------------------+---------------------+-------------+--------+------+------+-----------------+--------------------+------------------------+------------------------+ | 2 | new-project | | | 1 | NULL | 2024-10-22 14:39:32 | 2024-10-22 14:39:32 | new-project | 1 | 1 | 2 | 0 | NULL | NULL | NULL | +----+-------------+-------------+----------+-----------+-----------+---------------------+---------------------+-------------+--------+------+------+-----------------+--------------------+------------------------+------------------------+ 1 row in set (0.00 sec)
- 3点目:ローカルサーバ上でポートフォワードするという手もある。
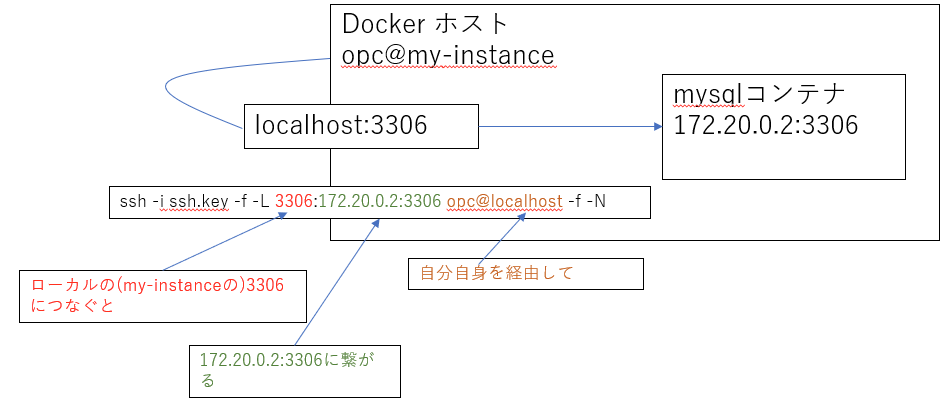
#ローカルサーバ上でポートフォワードを設定 # dockerホスト -> dockerホスト(踏み台相当) -> mysqlコンテナ(172.20.0.2:3306) の構成で、 # dockerホストのローカルの3306にアクセスすると、自分を経由してmysqlコンテナの3306へポートフォワードされる [root@my-instance ~]# ssh -i ssh.key -f -L 3306:172.20.0.2:3306 opc@localhost -f -N [root@my-instance ~]# mysql -h 127.0.0.1 -P 3306 -u redmine000kun -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 8.0.40 MySQL Community Server - GPL Copyright (c) 2000, 2024, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
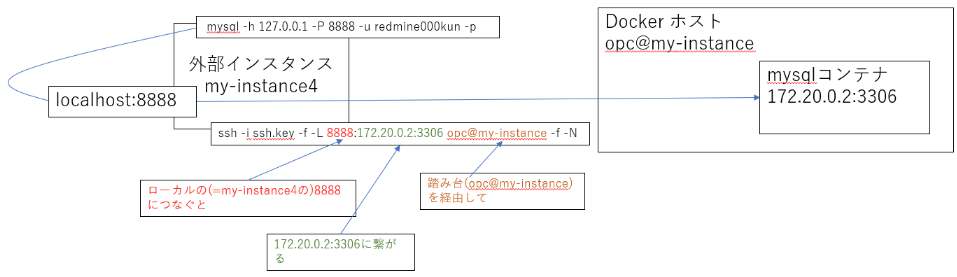
- コンテナが上がっているホストから見たコンテナのIPとポートがわかっていれば、外からでもポート転送でつなぐことができる
- OCIだとfirewalld, SELinux に注意
# 外部インスタンスから、sshポートフォワーディングを設定 # 外部インスタンス(my-instance4) -> dockerホスト(opc@my-instance) -> mysqlコンテナ(172.20.0.2:3306) の構成で、 # 外部インスタンスのローカルの8888にアクセスすると、dockerホスト経由でmysqlコンテナの3306へポートフォワードされる [root@my-instance4 ~]# ssh -i ssh.key -f -L 8888:172.20.0.2:3306 opc@my-instance -f -N [root@my-instance4 ~]# ps aux | grep 8888 | grep -v grep root 28881 0.0 0.1 186824 1012 ? Ss 00:16 0:00 ssh -i ssh.key -f -L 8888:172.20.0.2:3306 opc@my-instance -f -N # mysqlでローカルの8888にアクセス。(なぜかmysql -h localhost...とするとつながらないため注意) [root@my-instance4 ~]# mysql -h 127.0.0.1 -P 8888 -u redmine000kun -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 21 Server version: 8.0.40 MySQL Community Server - GPL Copyright (c) 2000, 2024, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Redmine + mariaDB
コンテナの起動
#ネットワークの作成 docker network create redmine000net3 #mariadbコンテナの作成 これは特にバージョン指定不要だった docker run --name mariadb000ex15 -dit --net=redmine000net3 -e MYSQL_ROOT_PASSWORD=mariarootpass -e MYSQL_DATABASE=redmine000db -e MYSQL_USER=redmine000kun -e MYSQL_PASSWORD=rkunpass mariadb --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password # redmineコンテナの作成 docker run -dit --name redmine000ex16 --network redmine000net3 -p 8087:3000 -e REDMINE_DB_MYSQL=mariadb000ex15 -e REDMINE_DB_DATABASE=redmine000db -e REDMINE_DB_USERNAME=redmine000kun -e REDMINE_DB_PASSWORD=rkunpass redmine # ブラウザでインスタンスの8087ポートにアクセス。デフォルトユーザはadmin/admin
後片付け
docker stop redmine000ex16 docker rm redmine000ex16 docker stop mariadb000ex15 docker rm mariadb000ex15 docker network rm redmine000net3
補足
同じ要領でmariadbにもローカルから接続できる。
mariadbはmysqlの妹分的存在で、mysql clientもそのままmariadbの接続に使える。
[root@my-instance ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mariadb000ex15 172.18.0.2 [root@my-instance ~]# mysql -h 172.18.0.2 -u redmine000kun -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 7 Server version: 11.5.2-MariaDB-ubu2404 mariadb.org binary distribution Copyright (c) 2000, 2024, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> mysql> mysql> mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | redmine000db | +--------------------+ 2 rows in set (0.01 sec) mysql>
WordPress + MariaDB
コンテナの起動
#ネットワークの作成 docker network create wordpress000net4 #mariadbコンテナの作成 docker run --name mariadb000ex17 -dit --net=wordpress000net4 -e MYSQL_ROOT_PASSWORD=mariarootpass -e MYSQL_DATABASE=wordpress000db -e MYSQL_USER=wordpress000kun -e MYSQL_PASSWORD=wkunpass mariadb --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password # redmineコンテナの作成 docker run --name wordpress000ex18 -dit --net=wordpress000net4 -p 8088:80 -e WORDPRESS_DB_HOST=mariadb000ex17 -e WORDPRESS_DB_NAME=wordpress000db -e WORDPRESS_DB_USER=wordpress000kun -e WORDPRESS_DB_PASSWORD=wkunpass wordpress # ブラウザでインスタンスの8088ポートにアクセス。
後片付け
docker stop wordpress000ex18 docker rm wordpress000ex18 docker stop mariadb000ex17 docker rm mariadb000ex17 docker network rm wordpress000net4
jupyter
https://qiita.com/fuku_tech/items/6752b00770552bf4f46b
# イメージをpull [root@my-instance ~]# docker pull jupyter/scipy-notebook Using default tag: latest Trying to pull repository docker.io/jupyter/scipy-notebook ... latest: Pulling from docker.io/jupyter/scipy-notebook aece8493d397: Pull complete fd92c719666c: Pull complete 088f11eb1e74: Pull complete 4f4fb700ef54: Pull complete ef8373d600b0: Pull complete 77e45ee945dc: Pull complete a30f89a0af6c: Pull complete dc42adc7eb73: Pull complete abaa8376a650: Pull complete aa099bb9e49a: Pull complete 822c4cbcf6a6: Pull complete d25166dcdc7b: Pull complete 964fc3e4ff9f: Pull complete 2c4c69587ee4: Pull complete de2cdd875fa8: Pull complete 75d33599f5f2: Pull complete 31973ea82470: Pull complete 96ee7e4439c7: Pull complete 1f9ad23c07ac: Pull complete d19266e0cb17: Pull complete 9a165b6e9dc7: Pull complete 5689442fd4e1: Pull complete 9a6a202f62a6: Pull complete 734ea0c3d94e: Pull complete a21a167f7127: Pull complete Digest: sha256:fca4bcc9cbd49d9a15e0e4df6c666adf17776c950da9fa94a4f0a045d5c4ad33 Status: Downloaded newer image for jupyter/scipy-notebook:latest jupyter/scipy-notebook:latest # jupyterのコンテナを起動。 # 本当は-dでバックグラウンド実行すべきだが、標準出力に出るトークンを見たいのでつけずに実行 [root@my-instance ~]# docker run -v /root/jupyter/:/home/jovyan/work -p 10000:8888 --name jupyter jupyter/scipy-notebook Entered start.sh with args: jupyter lab Running hooks in: /usr/local/bin/start-notebook.d as uid: 1000 gid: 100 Done running hooks in: /usr/local/bin/start-notebook.d Running hooks in: /usr/local/bin/before-notebook.d as uid: 1000 gid: 100 Done running hooks in: /usr/local/bin/before-notebook.d Executing the command: jupyter lab [I 2024-10-27 04:41:52.129 ServerApp] Package jupyterlab took 0.0000s to import [I 2024-10-27 04:41:52.321 ServerApp] Package jupyter_lsp took 0.1915s to import [W 2024-10-27 04:41:52.321 ServerApp] A `_jupyter_server_extension_points` function was not found in jupyter_lsp. Instead, a `_jupyter_server_extension_paths` function was found and will be used for now. This function name will be deprecated in future releases of Jupyter Server. [I 2024-10-27 04:41:52.329 ServerApp] Package jupyter_server_mathjax took 0.0076s to import [I 2024-10-27 04:41:52.399 ServerApp] Package jupyter_server_terminals took 0.0682s to import [I 2024-10-27 04:41:52.689 ServerApp] Package jupyterlab_git took 0.2901s to import [I 2024-10-27 04:41:52.718 ServerApp] Package nbclassic took 0.0278s to import [W 2024-10-27 04:41:52.742 ServerApp] A `_jupyter_server_extension_points` function was not found in nbclassic. Instead, a `_jupyter_server_extension_paths` function was found and will be used for now. This function name will be deprecated in future releases of Jupyter Server. [I 2024-10-27 04:41:52.743 ServerApp] Package nbdime took 0.0000s to import [I 2024-10-27 04:41:52.744 ServerApp] Package notebook took 0.0000s to import [I 2024-10-27 04:41:52.748 ServerApp] Package notebook_shim took 0.0000s to import [W 2024-10-27 04:41:52.749 ServerApp] A `_jupyter_server_extension_points` function was not found in notebook_shim. Instead, a `_jupyter_server_extension_paths` function was found and will be used for now. This function name will be deprecated in future releases of Jupyter Server. [I 2024-10-27 04:41:52.751 ServerApp] jupyter_lsp | extension was successfully linked. [I 2024-10-27 04:41:52.756 ServerApp] jupyter_server_mathjax | extension was successfully linked. [I 2024-10-27 04:41:52.761 ServerApp] jupyter_server_terminals | extension was successfully linked. [I 2024-10-27 04:41:52.767 ServerApp] jupyterlab | extension was successfully linked. [I 2024-10-27 04:41:52.800 ServerApp] jupyterlab_git | extension was successfully linked. [I 2024-10-27 04:41:52.833 ServerApp] nbclassic | extension was successfully linked. [I 2024-10-27 04:41:52.834 ServerApp] nbdime | extension was successfully linked. [I 2024-10-27 04:41:52.840 ServerApp] notebook | extension was successfully linked. [I 2024-10-27 04:41:52.846 ServerApp] Writing Jupyter server cookie secret to /home/jovyan/.local/share/jupyter/runtime/jupyter_cookie_secret [I 2024-10-27 04:41:54.005 ServerApp] notebook_shim | extension was successfully linked. [I 2024-10-27 04:41:54.146 ServerApp] notebook_shim | extension was successfully loaded. [I 2024-10-27 04:41:54.149 ServerApp] jupyter_lsp | extension was successfully loaded. [I 2024-10-27 04:41:54.150 ServerApp] jupyter_server_mathjax | extension was successfully loaded. [I 2024-10-27 04:41:54.151 ServerApp] jupyter_server_terminals | extension was successfully loaded. [I 2024-10-27 04:41:54.193 LabApp] JupyterLab extension loaded from /opt/conda/lib/python3.11/site-packages/jupyterlab [I 2024-10-27 04:41:54.193 LabApp] JupyterLab application directory is /opt/conda/share/jupyter/lab [I 2024-10-27 04:41:54.194 LabApp] Extension Manager is 'pypi'. [I 2024-10-27 04:41:54.197 ServerApp] jupyterlab | extension was successfully loaded. [I 2024-10-27 04:41:54.204 ServerApp] jupyterlab_git | extension was successfully loaded. [I 2024-10-27 04:41:54.225 ServerApp] nbclassic | extension was successfully loaded. [I 2024-10-27 04:41:54.558 ServerApp] nbdime | extension was successfully loaded. [I 2024-10-27 04:41:54.563 ServerApp] notebook | extension was successfully loaded. [I 2024-10-27 04:41:54.564 ServerApp] Serving notebooks from local directory: /home/jovyan [I 2024-10-27 04:41:54.564 ServerApp] Jupyter Server 2.8.0 is running at: [I 2024-10-27 04:41:54.564 ServerApp] http://b2e774832e5f:8888/lab?token=76c8930c86f7d77071b304514f5d00828072cefd355f3bdd [I 2024-10-27 04:41:54.564 ServerApp] http://127.0.0.1:8888/lab?token=76c8930c86f7d77071b304514f5d00828072cefd355f3bdd [I 2024-10-27 04:41:54.564 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 2024-10-27 04:41:54.598 ServerApp] To access the server, open this file in a browser: file:///home/jovyan/.local/share/jupyter/runtime/jpserver-7-open.html Or copy and paste one of these URLs: http://b2e774832e5f:8888/lab?token=76c8930c86f7d77071b304514f5d00828072cefd355f3bdd http://127.0.0.1:8888/lab?token=76c8930c86f7d77071b304514f5d00828072cefd355f3bdd [I 2024-10-27 04:41:57.517 ServerApp] Skipped non-installed server(s): bash-language-server, dockerfile-language-server-nodejs, javascript-typescript-langserver, jedi-language-server, julia-language-server, pyright, python-language-server, python-lsp-server, r-languageserver, sql-language-server, texlab, typescript-language-server, unified-language-server, vscode-css-languageserver-bin, vscode-html-languageserver-bin, vscode-json-languageserver-bin, yaml-language-server
画面に入り、表示されたトークンを以下に張りつけると利用できるようになる。
コンテナ・ホスト間のファイルのやり取り
ホストのファイルをコンテナへ
apacheコンテナのindes.htmlを更新する
# index.htmlを作る [root@my-instance ~]# cat index.html <html> <meta charset="utf-8"/> <body> <div>hello</div> </body> </html> #apacheコンテナを立てる [root@my-instance ~]# docker run --name apa000ex19 -d -p 8089:80 httpd 8ce61605615713aa8bf13deaffc749279cb2693881ee3488d9acf58e5ef2fffc [root@my-instance ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8ce616056157 httpd "httpd-foreground" 19 seconds ago Up 14 seconds 0.0.0.0:8089->80/tcp apa000ex19 # コンテナの初期状態での表示 [root@my-instance ~]# curl localhost:8089 <html><body><h1>It works!</h1></body></html> # これはコンテナ内の以下を表示している [root@my-instance ~]# docker exec -it apa000ex19 cat /usr/local/apache2/htdocs/index.html <html><body><h1>It works!</h1></body></html> # 上記ファイルを書き換える [root@my-instance ~]# docker cp index.html apa000ex19:/usr/local/apache2/htdocs/ # 更新された [root@my-instance ~]# curl localhost:8089 <html> <meta charset="utf-8"/> <body> <div>hello</div> </body> </html>
コンテナのファイルをホストへ
[root@my-instance ~]# docker cp apa000ex19:/usr/local/apache2/conf/httpd.conf . [root@my-instance ~]# ll 合計 32 -rw-r--r--. 1 root root 20827 10月 17 10:21 httpd.conf -rw-r--r--. 1 root root 75 10月 26 23:58 index.html -rw-------. 1 root root 1676 10月 22 23:09 ssh-key-2023-10-09.key
マウント
- ボリュームマウント
- ホストのdocker engineの領域に記憶領域を作ってマウントする
- 便利だが中身を外から操作しづらい → と言いつつ・・さわれないわけではない
- バインドマウント
- ホストの任意の場所にマウントする
- 外からも頻繁に触りたいに便利
バインドマウント
# バインドマウント用のローカルフォルダを作成 [root@my-instance apl_folder]# ll /root/apl_folder/ 合計 0 # ローカルフォルダをバインドマウントしたコンテナを作成 [root@my-instance apl_folder]# docker run --name apa000ex20 -d -p 8090:80 -v /root/apl_folder/:/usr/local/apache2/htdocs/ httpd 558902ba378cd202583af7d9f3057e77ae46f4496244512ec533e157729b4662 [root@my-instance apl_folder]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 558902ba378c httpd "httpd-foreground" 11 seconds ago Up 9 seconds 0.0.0.0:8090->80/tcp apa000ex20 # index.htmlがないので何もないリストが返ってくる [root@my-instance apl_folder]# curl localhost:8090 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head> <title>Index of /</title> </head> <body> <h1>Index of /</h1> <ul></ul> </body></html> # index.htmlを配置 [root@my-instance apl_folder]# mv ../index.html . # 再度curlするとローカルフォルダのindex.htmlを読んで返してくれるようになった [root@my-instance apl_folder]# curl localhost:8090 <html> <meta charset="utf-8"/> <body> <div>hello</div> </body> </html>
ちなみに上記のようにマウントした状態でコンテナ内のdfを確認したところ、特にマウントされている様子はなかった。謎。
[root@my-instance apl_folder]# docker exec -it apa000ex20 /bin/bash root@558902ba378c:/usr/local/apache2# df Filesystem 1K-blocks Used Available Use% Mounted on overlay 40223552 16107140 24116412 41% / tmpfs 65536 0 65536 0% /dev tmpfs 342452 0 342452 0% /sys/fs/cgroup shm 65536 0 65536 0% /dev/shm /dev/sda3 40223552 16107140 24116412 41% /etc/hosts tmpfs 342452 0 342452 0% /proc/acpi tmpfs 342452 0 342452 0% /proc/scsi tmpfs 342452 0 342452 0% /sys/firmware # docker inspect するとバインドマウントされている様子が見える [root@my-instance apl_folder]# docker container inspect apa000ex20 | jq '.[].Mounts' [ { "Type": "bind", "Source": "/root/apl_folder", "Destination": "/usr/local/apache2/htdocs", "Mode": "", "RW": true, "Propagation": "rprivate" } ]
ボリュームマウント
# dockerボリューム作成 [root@my-instance apl_folder]# docker volume create apa000vol1 apa000vol1 [root@my-instance apl_folder]# docker volume ls DRIVER VOLUME NAME local 1d6415cfe09a4c72b2669d5ca068c0ff93ef6a7f877b884e8402c9dc4f63b4f2 local 3cc3660295496ad9b7dbcce128c97e47a2a34889b92ab78778b27375f7d39318 local 3feaf2e16926b27f55413c419b7959782232490abf814f9757a8fa583188c5c3 local 6b4cd49b01d3c25b75173bc98a9520e7be0db0a6c4f1e45183989ac1f6b6d96f local 9b769b5711f74e489239274fd43ce09f42aedff44273688cda669db330bb354a local 10f4e38cd3177a7efefec3053ed0920592f35f76845c8e4840edce7e6e483581 local 42efef89359fc9b8c2ad88b5e466c2964a277f0073eac23806a5fc6e4ca26761 local 46d65079c0e79a4b5400518833411eca416624983de88a038beed2595e180876 local 992ad43ad550eb5cbaf7e6729919be16c5500957028c621a193d78f6996f13c2 local 43701ef98454dcbd3f9d9c0a389fa2ebfce3aec753bfa7e5f7896be51b38a235 local 94872215cf129b137111a3d915c82571d721bcd69f9f4eefc6e57cc3bfee080a local a48ad7868f7a2c37d03349d410d54786d35c6f8753c3a3dfdb59e35c8a36f99f local ab8dbe6646f1750fe506b955fd0fcf89dc3c3940141da45217e0f0be3590291e local apa000vol1 local cf0d139c7a6a033cc7cda700926ecf78489871c370935bfaec8884c8267ff91f local d8c84d6cb508782820803456190ef5d2a1a041c742094b625a7fee6d9fbfee82 local ddd87e77d73b251459c3be0c3d17f0ac2f343af6a47760e706bfa885ece02722 local f42fab4ac7941b27fb9b5b77796bb37ce1f3939fe2282468e3532279836057ce # 今の状態 [root@my-instance apl_folder]# docker volume inspect apa000vol1 [ { "CreatedAt": "2024-10-27T13:09:27+09:00", "Driver": "local", "Labels": {}, "Mountpoint": "/var/lib/docker/volumes/apa000vol1/_data", "Name": "apa000vol1", "Options": {}, "Scope": "local" } ]
# dockerボリュームをマウント [root@my-instance apl_folder]# docker run --name apa000ex21 -d -p 8091:80 -v apa000vol1:/usr/local/apache2/htdocs/ httpd 2a70b9370125308baf7e8104b565c038db76feef82a3489a16e585e06dab6ce4 # ボリュームの表示は特に変わらず。マウントされているかどうかをvolume自身は意識していない [root@my-instance apl_folder]# docker volume inspect apa000vol1 [ { "CreatedAt": "2024-10-27T13:22:50+09:00", "Driver": "local", "Labels": {}, "Mountpoint": "/var/lib/docker/volumes/apa000vol1/_data", "Name": "apa000vol1", "Options": {}, "Scope": "local" } ] # コンテナのmountの状態にマウント先が/var/lib/docker/volumes/apa000vol1/_dataと出ている。 # これがdocker volumeの実体? [root@my-instance apl_folder]# docker container inspect apa000ex21 | jq '.[].Mounts' [ { "Type": "volume", "Name": "apa000vol1", "Source": "/var/lib/docker/volumes/apa000vol1/_data", "Destination": "/usr/local/apache2/htdocs", "Driver": "local", "Mode": "z", "RW": true, "Propagation": "" } ] # 確かにhttpdコンテナのindex.htmlがここに配置されている。 [root@my-instance apl_folder]# ll /var/lib/docker/volumes/apa000vol1/_data/ 合計 4 -rw-r--r--. 1 501 ftp 45 6月 12 2007 index.html
コンテナのイメージ化
今あるコンテナをイメージに焼く
# 普通のhttpdコンテナを作成 [root@my-instance ~]# docker run --name apa000ex22 -d -p 8092:80 httpd ff66a1e6ae5128062035a1a0ff2424b9a8dacdf8d5e7e7fcea93779efddda1d8 # この時点ではindex.htmlの中身はhttpdコンテナのデフォルトのまま。 [root@my-instance ~]# curl localhost:8092 <html><body><h1>It works!</h1></body></html> # コンテナ上のindex.htmlを書き換え [root@my-instance apl_folder]# docker cp index.html apa000ex22:/usr/local/apache2/htdocs/ # 中身が更新された [root@my-instance apl_folder]# curl localhost:8092 <html> <meta charset="utf-8"/> <body> <div>hello</div> </body> </html> # 今のコンテナの状態でイメージを作成 [root@my-instance apl_folder]# docker commit apa000ex22 ex22_original1 sha256:8381b1d317e3bf778f966096f8f9dc2d58af390c543d0163b111896439c568fe # イメージが作成された [root@my-instance apl_folder]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE ex22_original1 latest 8381b1d317e3 5 seconds ago 148MB ★ wordpress latest d9da5214e7fd 11 days ago 699MB mysql latest be960704dfac 12 days ago 602MB mysql 8.0 03a8d6b00bce 12 days ago 590MB nginx latest 3b25b682ea82 3 weeks ago 192MB mariadb latest 4b8711c6c639 7 weeks ago 407MB httpd latest 1bcf11fa154f 3 months ago 148MB redmine latest c6f11346815b 4 months ago 633MB jupyter/scipy-notebook latest ad65fcfebde3 12 months ago 4.14GB # 作成したイメージから新しいコンテナを立てる [root@my-instance apl_folder]# docker run --name apa000ex22_2 -d -p 8888:80 ex22_original1 7edc68e70bb7d1b35166be38037c36b18dd3bcfec0ae9dd18848bcb7211e594d # 書き換えた内容が反映されている(index.htmlが書き変わった状態でイメージが作成されている) [root@my-instance apl_folder]# curl localhost:8888 <html> <meta charset="utf-8"/> <body> <div>hello</div> </body> </html>
Dockerfileを使う
- 「イメージの改造の仕方」を記述するファイル。
- ファイル名は
Dockerfilieで固定。1フォルダにつき1Dockerfileしか置けない。
# Dockerfileと、書き換え用のindex.htmlを準備。 [root@my-instance apl_folder]# pwd /root/apl_folder [root@my-instance apl_folder]# ll 合計 8 -rw-r--r--. 1 root root 53 10月 27 14:17 Dockerfile -rw-r--r--. 1 root root 134 10月 27 14:18 index.html [root@my-instance apl_folder]# cat Dockerfile FROM httpd COPY index.html /usr/local/apache2/htdocs [root@my-instance apl_folder]# cat index.html <html> <meta charset="utf-8"/> <body> <div>hello. this files is introduced to container image by DockerFile</div> </body> </html> [root@my-instance apl_folder]# docker build -t ex22_original2 /root/apl_folder/ Sending build context to Docker daemon 3.072kB Step 1/2 : FROM httpd ---> 1bcf11fa154f Step 2/2 : COPY index.html /usr/local/apache2/htdocs ---> 356ad7a1ae0f Successfully built 356ad7a1ae0f Successfully tagged ex22_original2:latest # イメージが作成された [root@my-instance apl_folder]# docker image ls | grep ex ex22_original2 latest 356ad7a1ae0f 2 minutes ago 148MB ex22_original1 latest 8381b1d317e3 11 minutes ago 148MB # このイメージでコンテナを作成すると、確かにindex.htmlの中身が書き変わった状態でイメージが作られていたことがわかる [root@my-instance apl_folder]# docker run --name apa000ex22_3 -d -p 8888:80 ex22_original2 9722291ee16350184d7340248ed6ff56397aecdf78fb29433e4a1b577102dc59 [root@my-instance apl_folder]# curl localhost:8888 <html> <meta charset="utf-8"/> <body> <div>hello. this files is introduced to container image by DockerFile</div> </body> </html>
イメージのインポート・エクスポート
[root@my-instance apl_folder]# docker image ls ex22_original2 REPOSITORY TAG IMAGE ID CREATED SIZE ex22_original2 latest 356ad7a1ae0f 16 minutes ago 148MB # イメージをsave [root@my-instance apl_folder]# docker save -o httpd_original.tar ex22_original2 [root@my-instance apl_folder]# ll -h httpd_original.tar -rw-------. 1 root root 146M 10月 27 14:28 httpd_original.tar # dokcer上のイメージをいったん削除 [root@my-instance apl_folder]# docker image rm ex22_original2:latest Untagged: ex22_original2:latest Deleted: sha256:356ad7a1ae0f3ccfd08f59c11fc2cb65799ba91d308fa590c994ec144fbc9739 Deleted: sha256:59c6677e995f824587c93509b88b371aabbca27e168a4698fdc6f067d4268e09 # イメージが削除された [root@my-instance apl_folder]# docker image ls ex22_original2 REPOSITORY TAG IMAGE ID CREATED SIZE # 書き出したtarファイルからイメージをload [root@my-instance apl_folder]# docker load -i httpd_original.tar f8d672255375: Loading layer [==================================================>] 4.096kB/4.096kB Loaded image: ex22_original2:latest # 消したイメージを再度ロードして復活させることができた。名前を変えられないのが若干不便 [root@my-instance apl_folder]# docker image ls ex22_original2 REPOSITORY TAG IMAGE ID CREATED SIZE ex22_original2 latest 356ad7a1ae0f 17 minutes ago 148MB
docker レジストリ
docker hubにアカウントを作って登録するか、プライベートレジストリを作る。
後者の例が以下
リポジトリ:各イメージを保存しておく領域・・という意味と思われるが、実用上はイメージ名と同義。
- タグ:イメージを一意に特定する情報として、「レジストリ名/リポジトリ名:バージョン」を指してタグということもあるが、単にバージョン情報の部分を指してタグという場合もある模様。
# プライベートレジストリをコンテナとして建てる [root@my-instance apl_folder]# docker run -d -p 5000:5000 registry Unable to find image 'registry:latest' locally Trying to pull repository docker.io/library/registry ... latest: Pulling from docker.io/library/registry 1cc3d825d8b2: Pull complete 85ab09421e5a: Pull complete 40960af72c1c: Pull complete e7bb1dbb377e: Pull complete a538cc9b1ae3: Pull complete Digest: sha256:ac0192b549007e22998eb74e8d8488dcfe70f1489520c3b144a6047ac5efbe90 Status: Downloaded newer image for registry:latest 685ab2fe3f09d8718b92de4f08fab3a4862d3f92e3ad90c6f4bb04bd69553218 [root@my-instance apl_folder]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 685ab2fe3f09 registry "/entrypoint.sh /etc…" 9 seconds ago Up 6 seconds 0.0.0.0:5000->5000/tcp naughty_boyd # 以下が先ほど作った自作イメージ [root@my-instance apl_folder]# docker image ls ex22_original2 REPOSITORY TAG IMAGE ID CREATED SIZE ex22_original2 latest 356ad7a1ae0f 30 minutes ago 148MB # プライベートレジストリに登録するべく、自作イメージを正式にタグ付けする。 # レジストリ名 → プライベートレジストリなのでlocalhost:5000 # リポジトリ名(=イメージ名) → myapacheのバージョン1 [root@my-instance apl_folder]# docker tag ex22_original2 localhost:5000/myapache:1 # 同じ内容で別タグが付いたイメージが新たに作成される [root@my-instance apl_folder]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE ex22_original2 latest 356ad7a1ae0f 31 minutes ago 148MB localhost:5000/myapache 1 356ad7a1ae0f 31 minutes ago 148MB ... # イメージをプライベートレジストリにpush [root@my-instance apl_folder]# docker push localhost:5000/myapache:1 The push refers to repository [localhost:5000/myapache] f8d672255375: Pushed 2293e5351a0e: Pushed 9748900c01ea: Pushed 18db38bc6851: Pushed 5f70bf18a086: Pushed 25326f665290: Pushed 98b5f35ea9d3: Pushed 1: digest: sha256:c9c15c062c8bdbd8e5ba2ac5d212679f5d7bfb7d91c8a2967d0142f970b14a02 size: 1779 # プライベートレジストリの登録状況を確認 # https://qiita.com/takuyaWt/items/ce846b7f73d8635b5b7b # リポジトリ一覧(=イメージ一覧)を確認 → myapahceが登録されている [root@my-instance apl_folder]# curl http://localhost:5000/v2/_catalog {"repositories":["myapache"]} # myapacheリポジトリ(myapacheイメージ)のタグ(=バージョン情報) → バージョン1が登録されている [root@my-instance apl_folder]# curl http://localhost:5000/v2/myapache/tags/list {"name":"myapache","tags":["1"]} # 確認のためローカルに存在するイメージをいったん削除 [root@my-instance apl_folder]# docker image rm ex22_original2:latest Untagged: ex22_original2:latest [root@my-instance apl_folder]# docker image rm localhost:5000/myapache:1 Untagged: localhost:5000/myapache:1 Untagged: localhost:5000/myapache@sha256:c9c15c062c8bdbd8e5ba2ac5d212679f5d7bfb7d91c8a2967d0142f970b14a02 Deleted: sha256:356ad7a1ae0f3ccfd08f59c11fc2cb65799ba91d308fa590c994ec144fbc9739 Deleted: sha256:59c6677e995f824587c93509b88b371aabbca27e168a4698fdc6f067d4268e09 [root@my-instance apl_folder]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE ... # プライベートレジストリからmyapache:1をダウンロード [root@my-instance apl_folder]# docker pull localhost:5000/myapache:1 Trying to pull repository localhost:5000/myapache ... 1: Pulling from localhost:5000/myapache a480a496ba95: Already exists 3a2663e66670: Already exists 4f4fb700ef54: Already exists dbde712f81fb: Already exists 867b2ea3628d: Already exists 6bd9d3710aae: Already exists 2752699539fa: Pull complete Digest: sha256:c9c15c062c8bdbd8e5ba2ac5d212679f5d7bfb7d91c8a2967d0142f970b14a02 Status: Downloaded newer image for localhost:5000/myapache:1 localhost:5000/myapache:1 # 無事イメージをダウンロードできた [root@my-instance apl_folder]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE localhost:5000/myapache 1 356ad7a1ae0f 49 minutes ago 148MB wordpress latest d9da5214e7fd 11 days ago 699MB mysql latest be960704dfac 12 days ago 602MB mysql 8.0 03a8d6b00bce 12 days ago 590MB nginx latest 3b25b682ea82 3 weeks ago 192MB mariadb latest 4b8711c6c639 7 weeks ago 407MB httpd latest 1bcf11fa154f 3 months ago 148MB redmine latest c6f11346815b 4 months ago 633MB jupyter/scipy-notebook latest ad65fcfebde3 12 months ago 4.14GB registry latest 75ef5b734af4 13 months ago 25.4MB
docker compose
- dockerfile
- イメージの作成ができる
- docker compose
- dockerのコンテナ・ボリューム・ネットワークの定義をyamlに書いて、dockerに実行させることができる。
- kubernetesのpodの概念に近いか。
docker-composeのインストール
少し前まではdocker コマンドの付属品としてdocker composeなるコマンドが利用できたが、今はdocker-compose という別コマンドを導入する必要がある。
https://qiita.com/youtangai/items/ff67ceff5497a0e0b1af
[root@my-instance apache]# curl -L https://github.com/docker/compose/releases/download/v2.29.7/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 100 60.8M 100 60.8M 0 0 5673k 0 0:00:10 0:00:10 --:--:-- 5884k [root@my-instance apache]# sudo chmod +x /usr/local/bin/docker-compose [root@my-instance apache]# docker-compose --version Docker Compose version v2.29.7
apacheを起動
# docker composeを書く [root@my-instance apache]# ll 合計 4 -rw-r--r--. 1 root root 103 10月 27 15:22 docker-compose.yml [root@my-instance apache]# [root@my-instance apache]# [root@my-instance apache]# [root@my-instance apache]# cat docker-compose.yml version: "3" services: apa000ex2: image: httpd ports: - 8080:80 restart: always # docker-composeでapacheを実行 [root@my-instance apache]# docker-compose -f docker-compose.yml up -d WARN[0000] /root/docker_compose_practice/apache/docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion [+] Running 2/2 ✔ Network apache_default Created 0.4s ✔ Container apache-apa000ex2-1 Started 3.6s # httpdコンテナが起動した [root@my-instance apache]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 148d25aad2f8 httpd "httpd-foreground" 11 seconds ago Up 7 seconds 0.0.0.0:8080->80/tcp apache-apa000ex2-1 [root@my-instance apache]# curl localhost:8080 <html><body><h1>It works!</h1></body></html> # docker-composeでapahceを消す(stopとrmが同時に行われる) [root@my-instance apache]# docker-compose -f docker-compose.yml down WARN[0000] /root/docker_compose_practice/apache/docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion [+] Running 2/2 ✔ Container apache-apa000ex2-1 Removed 2.7s ✔ Network apache_default Removed 0.2s # コンテナが消えた [root@my-instance apache]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
WordPress + MySQLを起動
# docker composeを書く [root@my-instance wordpress_mysql]# ll 合計 4 -rw-r--r--. 1 root root 797 10月 27 15:51 docker-compose.yml [root@my-instance wordpress_mysql]# cat docker-compose.yml version: '3' services: mysql000ex11: image: mysql:5.7 networks: - wordpress000net1 volumes: - mysql000vol11:/var/lib/mysql restart: always environment: MYSQL_ROOT_PASSWORD: myrootpass MYSQL_DATABASE: wordpress000db MYSQL_USER: wordpress000kun MYSQL_PASSWORD: wkunpass wordpress000ex12: depends_on: - mysql000ex11 image: wordpress networks: - wordpress000net1 volumes: - wordpress000vol12:/var/www/html ports: - 8085:80 restart: always environment: WORDPRESS_DB_HOST: mysql000ex11 WORDPRESS_DB_NAME: wordpress000db WORDPRESS_DB_USER: wordpress000kun WORDPRESS_DB_PASSWORD: wkunpass networks: wordpress000net1: volumes: mysql000vol11: wordpress000vol12: # docker-composeでwordpress+mysqlを実行 [root@my-instance wordpress_mysql]# docker-compose -f docker-compose.yml up -d WARN[0000] /root/docker_compose_practice/wordpress_mysql/docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion [+] Running 12/12 ✔ mysql000ex11 Pulled 86.2s ✔ 20e4dcae4c69 Pull complete 40.0s ✔ 1c56c3d4ce74 Pull complete 40.3s ✔ e9f03a1c24ce Pull complete 40.7s ✔ 68c3898c2015 Pull complete 42.6s ✔ 6b95a940e7b6 Pull complete 42.8s ✔ 90986bb8de6e Pull complete 43.1s ✔ ae71319cb779 Pull complete 49.1s ✔ ffc89e9dfd88 Pull complete 49.3s ✔ 43d05e938198 Pull complete 83.6s ✔ 064b2d298fba Pull complete 83.9s ✔ df9a4d85569b Pull complete 84.1s [+] Running 5/5 ✔ Network wordpress_mysql_wordpress000net1 Created 0.3s ✔ Volume "wordpress_mysql_wordpress000vol12" Created 0.0s ✔ Volume "wordpress_mysql_mysql000vol11" Created 0.0s ✔ Container wordpress_mysql-mysql000ex11-1 Started 3.8s ✔ Container wordpress_mysql-wordpress000ex12-1 Started 7.2s # コンテナ・ボリューム・ネットワークが生成された [root@my-instance wordpress_mysql]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0f5592c088ab wordpress "docker-entrypoint.s…" 4 minutes ago Up 4 minutes 0.0.0.0:8085->80/tcp wordpress_mysql-wordpress000ex12-1 b633822bb178 mysql:5.7 "docker-entrypoint.s…" 4 minutes ago Up 4 minutes 3306/tcp, 33060/tcp wordpress_mysql-mysql000ex11-1 [root@my-instance wordpress_mysql]# docker volume ls | grep wordpress local wordpress_mysql_mysql000vol11 local wordpress_mysql_wordpress000vol12 [root@my-instance wordpress_mysql]# docker network ls | grep wordpress e131efea5fe7 wordpress_mysql_wordpress000net1 bridge local # 疎通もOK [root@my-instance wordpress_mysql]# curl localhost:8085 -v * About to connect() to localhost port 8085 (#0) * Trying ::1... * Connected to localhost (::1) port 8085 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: localhost:8085 > Accept: */* > < HTTP/1.1 302 Found < Date: Sun, 27 Oct 2024 07:02:29 GMT < Server: Apache/2.4.62 (Debian) < X-Powered-By: PHP/8.2.24 < Expires: Wed, 11 Jan 1984 05:00:00 GMT < Cache-Control: no-cache, must-revalidate, max-age=0 < X-Redirect-By: WordPress < Location: http://localhost:8085/wp-admin/install.php < Content-Length: 0 < Content-Type: text/html; charset=UTF-8 < * Connection #0 to host localhost left intact # docker-composeで削除。 [root@my-instance wordpress_mysql]# docker-compose -f docker-compose.yml down WARN[0000] /root/docker_compose_practice/wordpress_mysql/docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion [+] Running 3/3 ✔ Container wordpress_mysql-wordpress000ex12-1 Removed 3.7s ✔ Container wordpress_mysql-mysql000ex11-1 Removed 3.4s ✔ Network wordpress_mysql_wordpress000net1 Removed 0.2s # コンテナのネットワークは消えるが、ボリュームは残る。 [root@my-instance wordpress_mysql]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES [root@my-instance wordpress_mysql]# [root@my-instance wordpress_mysql]# docker volume ls | grep wordpress local wordpress_mysql_mysql000vol11 local wordpress_mysql_wordpress000vol12 [root@my-instance wordpress_mysql]# docker network ls | grep wordpress